
python爬取百度图片的思路与代码(最后附上了代码)
posted on 2023-06-06 11:44 read(1200) comment(0) like(30) collect(1)
Python crawling Baidu pictures is generally relatively simple. The idea of crawling a website and crawling Baidu pictures is also very traceable. The idea is divided into two parts. The first part (web page analysis of Baidu pictures): Baidu pictures is a dynamic web page, how to judge whether a web page is a dynamic web page or a static web page. It is also relatively simple, and there are many resources on the Internet. To put it simply: If the content you want to crawl is rarely (incompletely or not) in the page source code, and the URL is iconic? . Basically a dynamic web page.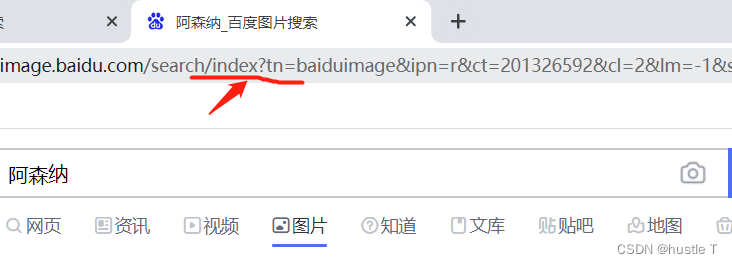
Therefore, it is basically judged that the web page of Baidu pictures is a dynamic web page. This dynamic web page constantly interacts with the database. We can't get the address of the photo in the source code of the page, or there may be 20 pictures (in some websites). And static web pages are basically all the content we can find in the source code of the page. So the first part of the analysis of ideas is completed, that is, we crawl for dynamic web pages.
The second part of the idea (code to achieve crawling pictures): first open the developer tool (F12) of the browser, then lock the network (network), and then lock the fetch/xhr. In json, there is hidden information about each image. Picture it!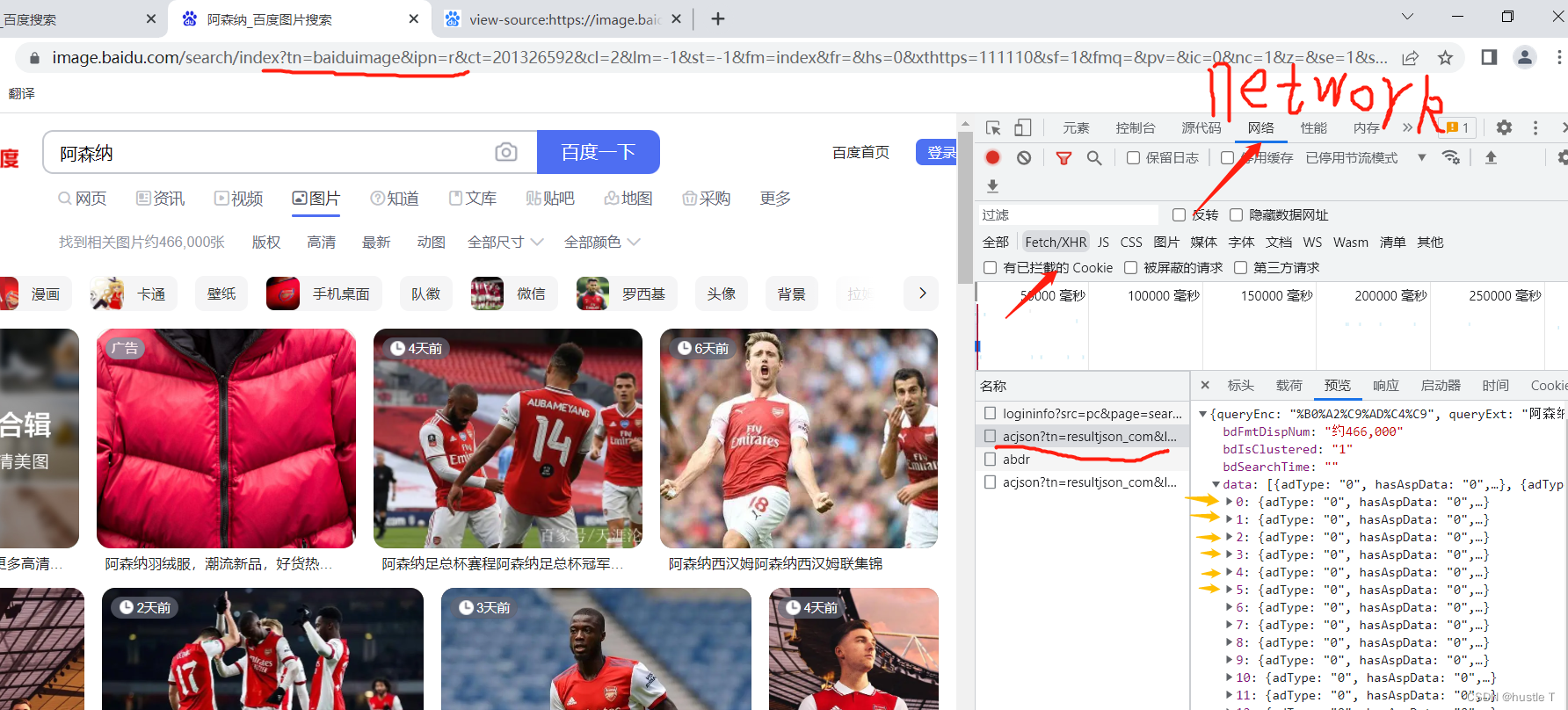
Whenever you visit and you continue to visit more photos, it will pass in a new file starting with acjson, which can vividly feel the dynamics. In these files starting with acjson, the page source code contains the access address of its new photo. You only need to let the program access the source code in the acjson web page, and you can use regular expressions to match each The address of the photo, the last accessed image, downloaded to your computer. Or somewhere else. That's the way of thinking. So find the law of these acjson files: each data number in it has 30 corresponding to 30 photos, and the url address pn of the acjson is an arithmetic sequence of 30 each time. Then the rules come out. In fact, we can complete this demo by nesting two loops. The first layer accesses the source code of the file beginning with acjson, the second layer is the url of each photo, and finally writes it to the computer. Finish! ! !
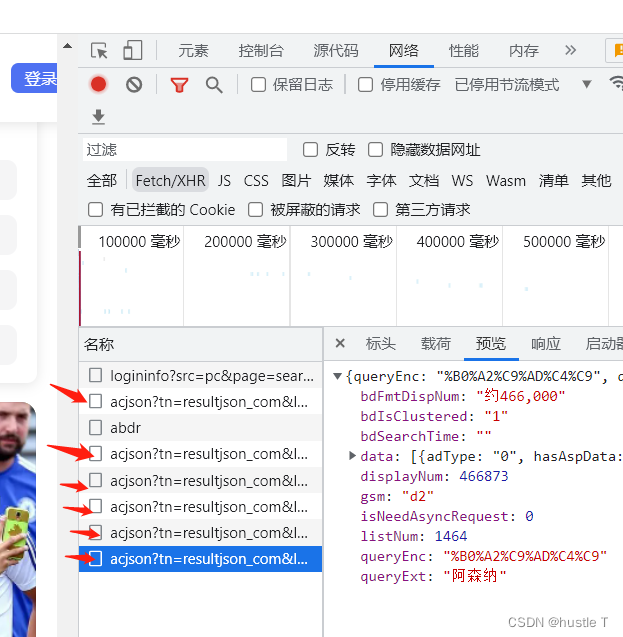
The url address of acjson is in the header, and its regular pn changes (the other parameters behind it don’t matter)
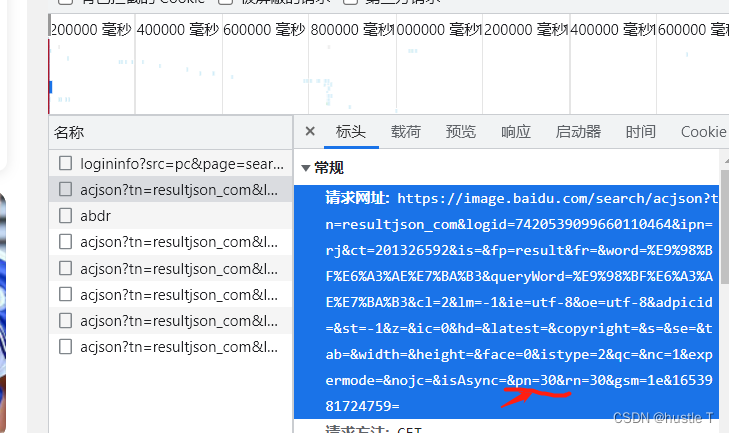
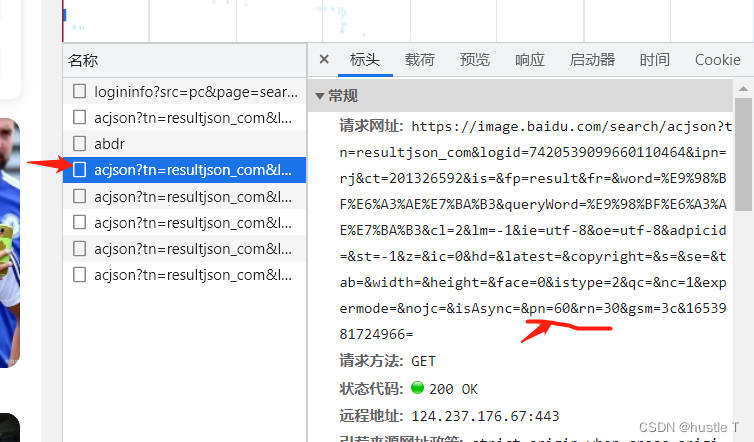
Then the idea is understood, the code is as follows. Another point is that when a crawler visits Baidu pictures, it is likely to encounter Baidu verification and be discovered, and the forbidden spider will pop up. To pretend to be a browser. In your request header, just copy the various parameters of the browser!
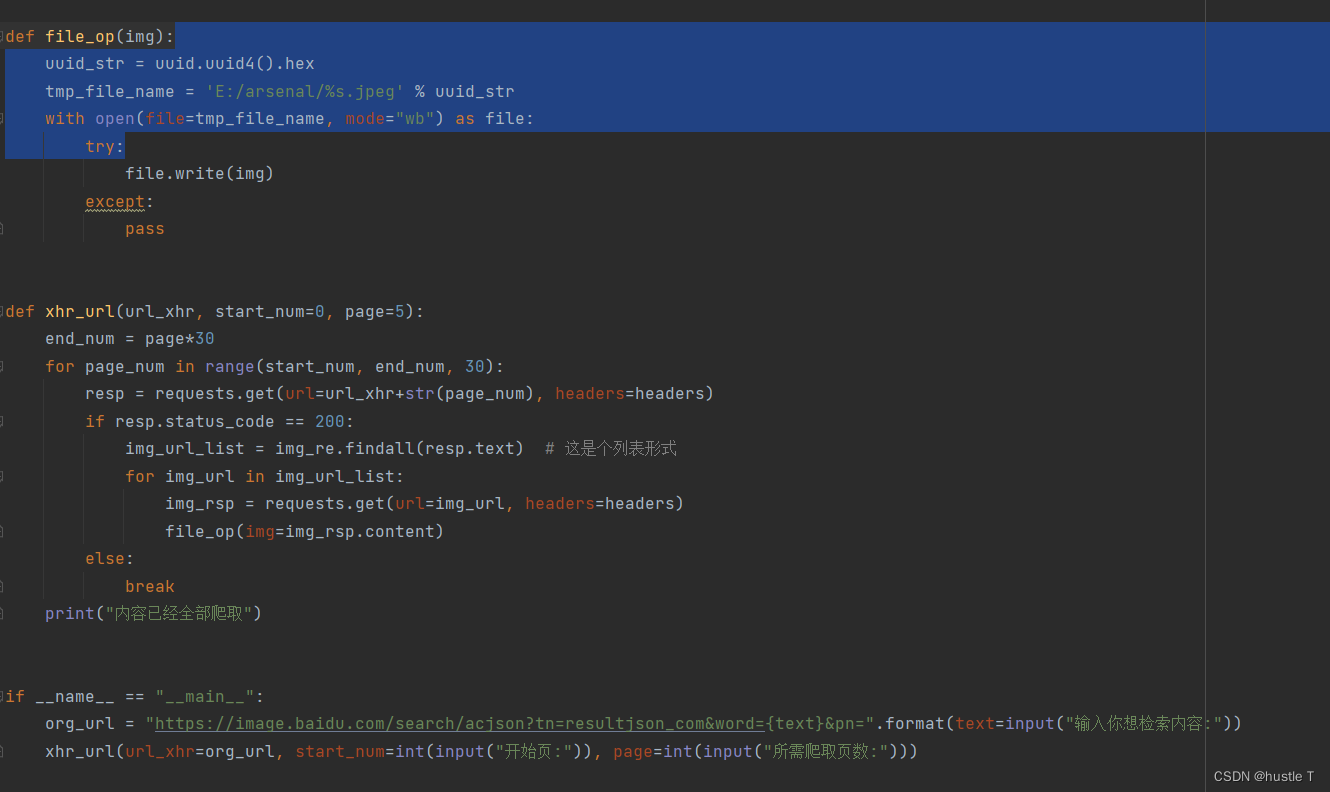
from fake_useragent import UserAgent
import requests
import re
import uuid
headers = {"User-agent": UserAgent().random, # Randomly generate a proxy request
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Connection": "keep-alive"}
img_re = re.compile('"thumbURL":"(.*?)"')
img_format = re.compile("f=(.*).*?w")
def file_op(img):
uuid_str = uuid.uuid4().hex
tmp_file_name = 'E:/arsenal/%s.jpeg' % uuid_str
with open(file=tmp_file_name, mode="wb") as file:
try:
file.write(img)
except:
pass
def xhr_url(url_xhr, start_num=0, page=5):
end_num = page*30
for page_num in range(start_num, end_num, 30):
resp = requests.get(url=url_xhr+str(page_num), headers=headers)
if resp.status_code == 200:
img_url_list = img_re.findall(resp.text) # This is a list form
for img_url in img_url_list:
img_rsp = requests.get(url=img_url, headers=headers)
file_op(img=img_rsp.content)
else:
break
print("All content has been crawled")
if __name__ == "__main__":
org_url = "https://image.baidu.com/search/acjson?tn=resultjson_com&word={text}&pn=".format(text=input("Enter the content you want to retrieve:"))
xhr_url(url_xhr=org_url, start_num=int(input("Start page:")), page=int(input("Number of pages to crawl:")))
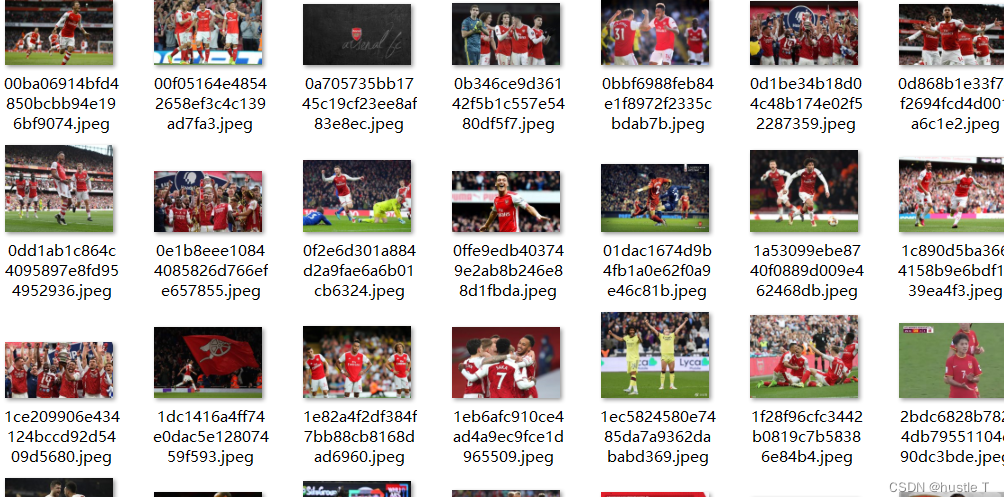
Run the results to see it

Category of website: technical article > Blog
Author:evilangel
link:http://www.pythonblackhole.com/blog/article/80234/5b6ae34b29b4205da4ac/
source:python black hole net
Please indicate the source for any form of reprinting. If any infringement is discovered, it will be held legally responsible.
name:
Comment content: (supports up to 255 characters)
no articles