
随机森林算法(Random Forest)原理分析及Python实现
posted on 2023-05-21 18:06 read(990) comment(0) like(20) collect(3)
Table of contents
1. Basic concepts
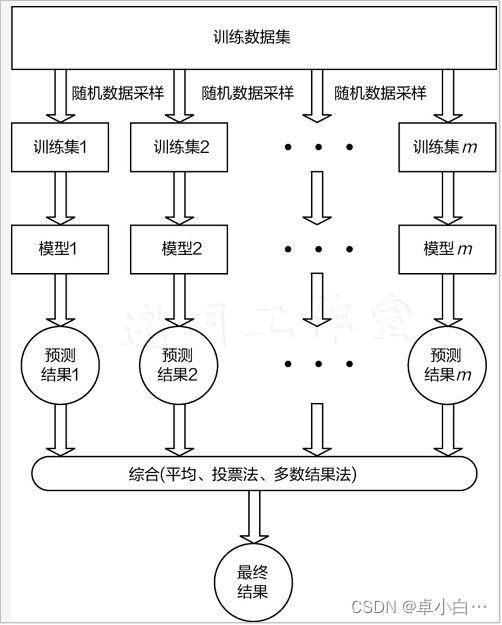
Random forest is one of the most practical algorithms in bagging ensemble strategies. The forest is to build multiple decision trees separately, and put them together to form a forest. These decision trees are all built to solve the same task, and the final goals are also consistent. Finally, the results can be averaged, as shown in the figure shown.
1. Supervised machine learning
A function (model parameters) is learned from a given training data set, and when new data arrives, results can be predicted based on this function. The training set requirements for supervised learning include input and output, which can also be said to be features and targets. Objects in the training set are annotated by humans. Supervised learning is the most common classification problem. An optimal model (this model belongs to a set of functions and optimally represents a certain evaluation criterion) is obtained by training existing training samples (that is, known data and their corresponding outputs). The following is the best), and then use this model to map all the inputs to the corresponding output, and make a simple judgment on the output to achieve the purpose of classification. It also has the ability to classify unknown data. The goal of supervised learning is often to let the computer learn the classification system (model) that we have created.
Supervised learning is a common technique for training neural networks and decision trees . These two technologies are highly dependent on the information given by the pre-determined classification system. For neural networks, the classification system uses information to judge the error of the network, and then continuously adjusts the network parameters. With decision trees, classification systems use it to determine which attributes provide the most information.
2. Regression and classification
Both regression and classification are supervised machine learning problems that are used to predict an outcome or the value or category of an outcome. Their difference is:
Classification problems are used to put a label on things, usually the result is a discrete value. For example, to judge whether the animal in a picture is a cat or a dog, the classification is usually based on regression, and the classification does not have the concept of approximation. There is only one correct result in the end, and the wrong one is wrong, and there will be no similar ones. concept. The most common classification method is logistic regression , or logistic classification.
Regression problems are usually used to predict a value, such as predicting housing prices, future weather conditions, etc. For example, the actual price of a product is 500 yuan, and the predicted value through regression analysis is 499 yuan. This is a relatively good regression analysis. Regression is an approximate prediction of the true value.
A simple way to distinguish between the two can be roughly stated that classification is about predicting labels (such as "spam" or "not spam"), while regression is about predicting quantities.
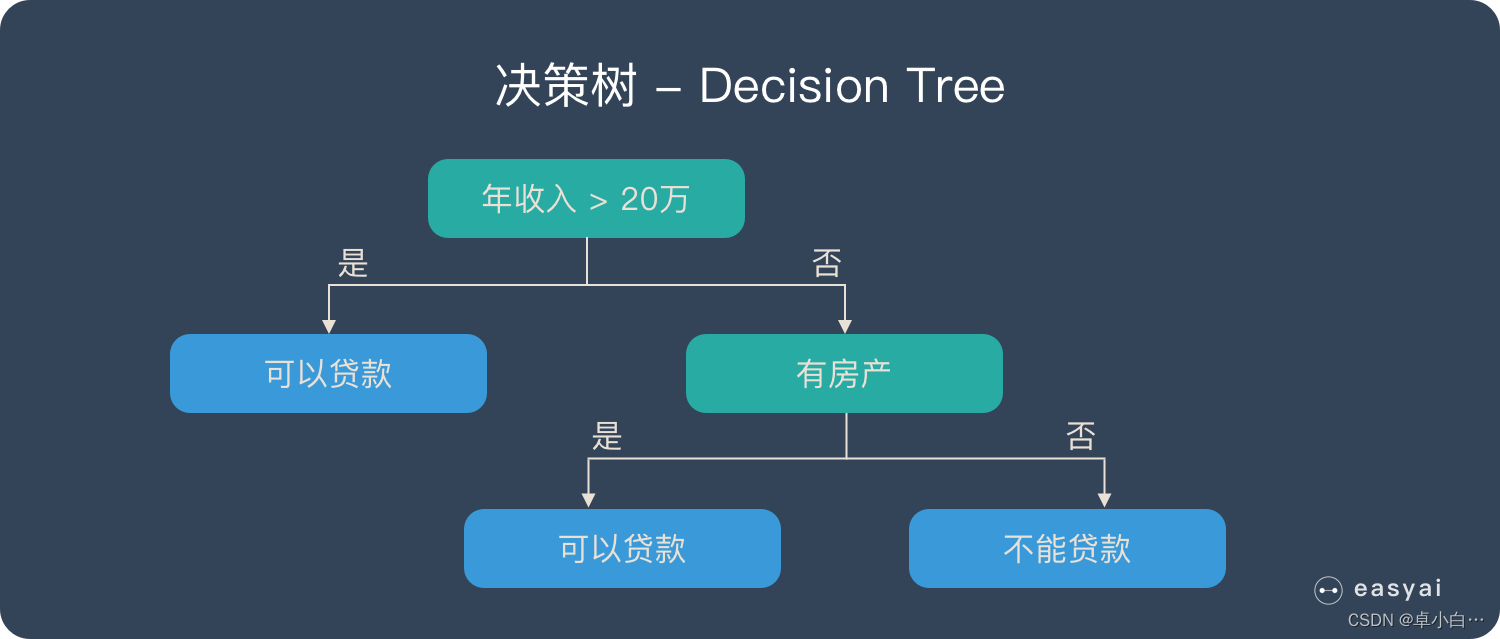
3. Decision tree
Decision tree is a very simple algorithm, which is highly explanatory and conforms to human intuitive thinking. This is a supervised learning algorithm based on if-then-else rules. The following figure can intuitively express the logic of the decision tree.
4. Random Forest
A random forest is composed of many decision trees, and there is no correlation between different decision trees. When we perform a classification task, when a new input sample enters, each decision tree in the forest is judged and classified separately. Each decision tree will get its own classification result, which classification in the classification result of the decision tree At most, then Random Forest will take this result as the final result.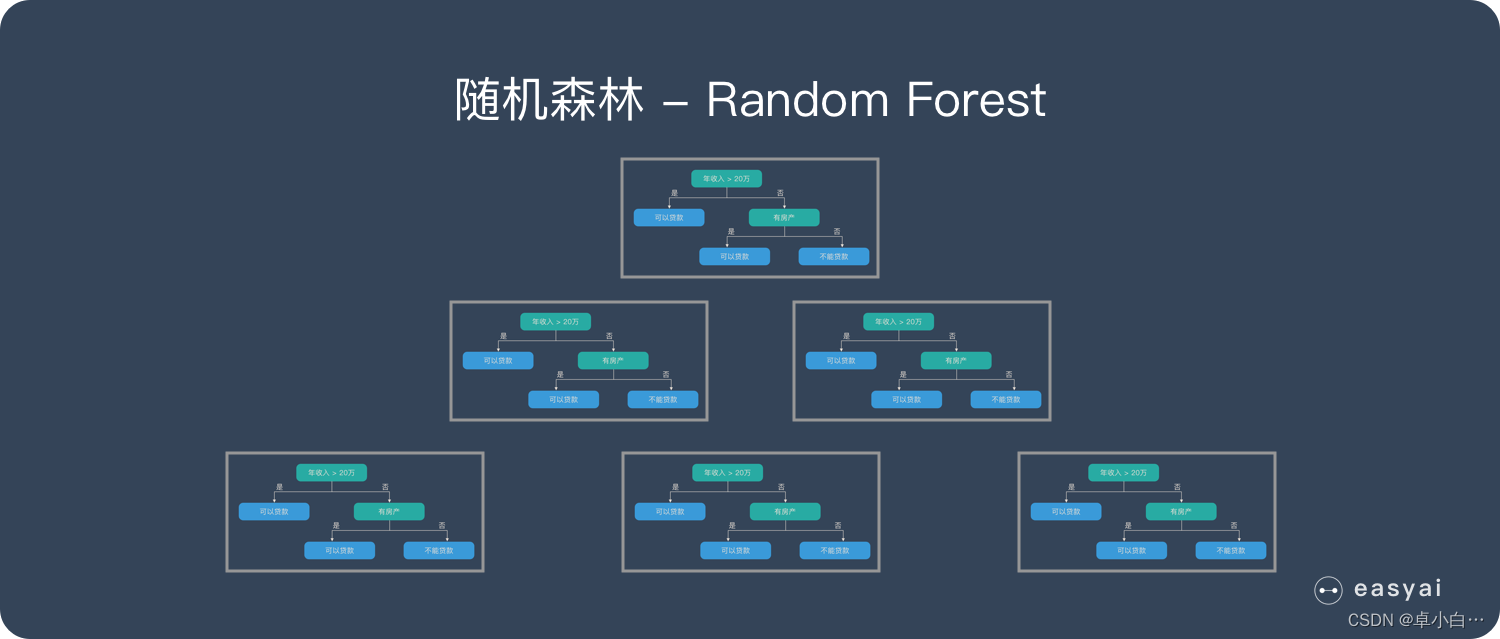
2. The structure of Random Forest

1. Algorithm implementation
- A sample with a sample size of N is drawn N times with replacement, one sample is drawn each time, and finally N samples are formed. The selected N samples are used to train a decision tree as samples at the root node of the decision tree.
- When each sample has M attributes, when each node of the decision tree needs to be split, m attributes are randomly selected from the M attributes, satisfying the condition m << M. Then use a certain strategy (for example, information gain) from these m attributes to select 1 attribute as the splitting attribute of the node.
- In the process of forming the decision tree, each node must be split according to step 2 (it is easy to understand, if the attribute selected by the node next time is the attribute used when its parent node was just split, the node has reached the leaf node, there is no need to continue to split), until it can no longer be split. Note that no pruning is performed throughout the formation of the decision tree.
- Follow steps 1-3 to build a large number of decision trees, thus forming a random forest.
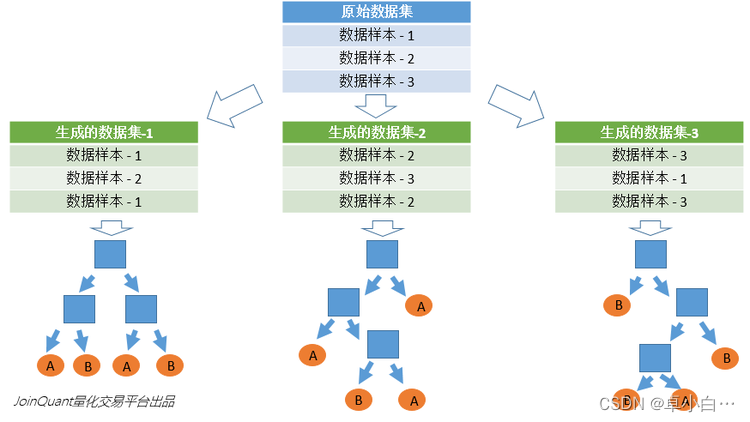
2. Random selection of data
- Sampling with replacement is taken from the original data set to construct a sub-data set, and the data volume of the sub-data set is the same as that of the original data set. Elements in different sub-datasets can be repeated, and elements in the same sub-dataset can also be repeated.
- Use sub-datasets to build sub-decision trees, put this data into each sub-decision tree, and each sub-decision tree outputs a result.
- If there is new data and the classification result needs to be obtained through the random forest, the output result of the random forest can be obtained by voting on the judgment result of the sub-decision tree.
As shown in the figure, suppose there are 3 sub-decision trees in the random forest, the classification result of 2 sub-trees is class A, and the classification result of 1 sub-tree is class B, then the classification result of random forest is A.
3. Random selection of features to be selected
Similar to the random selection of the data set, each split process of the subtree in the random forest does not use all the features to be selected, butRandomly select a certain feature from all the features to be selected, and then select the optimal feature among the randomly selected features. This can make the decision trees in the random forest different from each other, improve the diversity of the system, and thus improve the classification performance.
In the figure below, the blue squares represent all the features that can be selected, that is, the features to be selected. Yellow squares are split features. On the left is the feature selection process of a decision tree. The split is completed by selecting the optimal split feature among the features to be selected. On the right is the feature selection process for a subtree in a random forest.
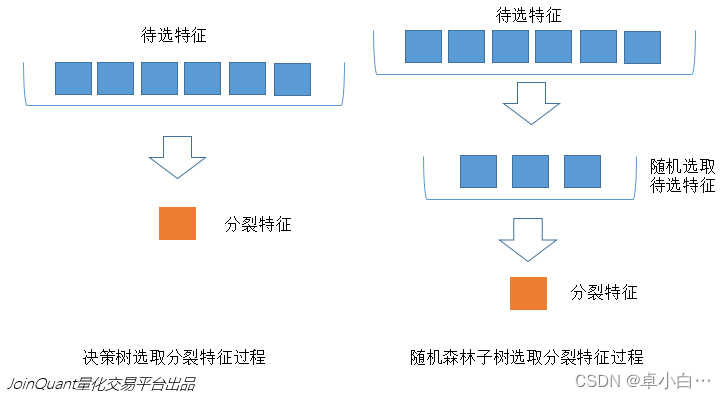
3. Advantages and disadvantages of Random Forest
1. Advantages
- It can produce very high-dimensional (many features) data without dimensionality reduction or feature selection
- Not prone to overfitting
- For unbalanced datasets, it balances the errors.
- Accuracy can still be maintained if a large fraction of features are missing.
2. Cons
- Random forests have been shown to overfit on some noisy classification or regression problems
- Since Random Forest uses many decision trees, it can require a lot of memory on larger projects. This can make it slower than some other more efficient algorithms
4. Python Implementation of Random Forest
1. Random forest python implementation
Code implementation process:
(1) Import the file and convert all features to float form
(2) Divide the data set into n parts to facilitate cross-validation
(3) Construct a subset of data (random sampling), and select the optimal feature under the specified number of features (assuming m, manual parameter adjustment)
(4) Construct a decision tree
(5) Create a random forest (combination of multiple decision trees)
(6) Input the test set and perform the test, and output the prediction result
# -*- coding: utf-8 -*-
import csv
from random import seed
from random import randrange
from math import sqrt
def loadCSV(filename):#加载数据,一行行的存入列表
dataSet = []
with open(filename, 'r') as file:
csvReader = csv.reader(file)
for line in csvReader:
dataSet.append(line)
return dataSet
# 除了标签列,其他列都转换为float类型
def column_to_float(dataSet):
featLen = len(dataSet[0]) - 1
for data in dataSet:
for column in range(featLen):
data[column] = float(data[column].strip())
# 将数据集随机分成N块,方便交叉验证,其中一块是测试集,其他四块是训练集
def spiltDataSet(dataSet, n_folds):
fold_size = int(len(dataSet) / n_folds)
dataSet_copy = list(dataSet)
dataSet_spilt = []
for i in range(n_folds):
fold = []
while len(fold) < fold_size: # 这里不能用if,if只是在第一次判断时起作用,while执行循环,直到条件不成立
index = randrange(len(dataSet_copy))
fold.append(dataSet_copy.pop(index)) # pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
dataSet_spilt.append(fold)
return dataSet_spilt
# 构造数据子集
def get_subsample(dataSet, ratio):
subdataSet = []
lenSubdata = round(len(dataSet) * ratio)#返回浮点数
while len(subdataSet) < lenSubdata:
index = randrange(len(dataSet) - 1)
subdataSet.append(dataSet[index])
# print len(subdataSet)
return subdataSet
# 分割数据集
def data_spilt(dataSet, index, value):
left = []
right = []
for row in dataSet:
if row[index] < value:
left.append(row)
else:
right.append(row)
return left, right
# 计算分割代价
def spilt_loss(left, right, class_values):
loss = 0.0
for class_value in class_values:
left_size = len(left)
if left_size != 0: # 防止除数为零
prop = [row[-1] for row in left].count(class_value) / float(left_size)
loss += (prop * (1.0 - prop))
right_size = len(right)
if right_size != 0:
prop = [row[-1] for row in right].count(class_value) / float(right_size)
loss += (prop * (1.0 - prop))
return loss
# 选取任意的n个特征,在这n个特征中,选取分割时的最优特征
def get_best_spilt(dataSet, n_features):
features = []
class_values = list(set(row[-1] for row in dataSet))
b_index, b_value, b_loss, b_left, b_right = 999, 999, 999, None, None
while len(features) < n_features:
index = randrange(len(dataSet[0]) - 1)
if index not in features:
features.append(index)
# print 'features:',features
for index in features:#找到列的最适合做节点的索引,(损失最小)
for row in dataSet:
left, right = data_spilt(dataSet, index, row[index])#以它为节点的,左右分支
loss = spilt_loss(left, right, class_values)
if loss < b_loss:#寻找最小分割代价
b_index, b_value, b_loss, b_left, b_right = index, row[index], loss, left, right
# print b_loss
# print type(b_index)
return {'index': b_index, 'value': b_value, 'left': b_left, 'right': b_right}
# 决定输出标签
def decide_label(data):
output = [row[-1] for row in data]
return max(set(output), key=output.count)
# 子分割,不断地构建叶节点的过程
def sub_spilt(root, n_features, max_depth, min_size, depth):
left = root['left']
# print left
right = root['right']
del (root['left'])
del (root['right'])
# print depth
if not left or not right:
root['left'] = root['right'] = decide_label(left + right)
# print 'testing'
return
if depth > max_depth:
root['left'] = decide_label(left)
root['right'] = decide_label(right)
return
if len(left) < min_size:
root['left'] = decide_label(left)
else:
root['left'] = get_best_spilt(left, n_features)
# print 'testing_left'
sub_spilt(root['left'], n_features, max_depth, min_size, depth + 1)
if len(right) < min_size:
root['right'] = decide_label(right)
else:
root['right'] = get_best_spilt(right, n_features)
# print 'testing_right'
sub_spilt(root['right'], n_features, max_depth, min_size, depth + 1)
# 构造决策树
def build_tree(dataSet, n_features, max_depth, min_size):
root = get_best_spilt(dataSet, n_features)
sub_spilt(root, n_features, max_depth, min_size, 1)
return root
# 预测测试集结果
def predict(tree, row):
predictions = []
if row[tree['index']] < tree['value']:
if isinstance(tree['left'], dict):
return predict(tree['left'], row)
else:
return tree['left']
else:
if isinstance(tree['right'], dict):
return predict(tree['right'], row)
else:
return tree['right']
# predictions=set(predictions)
def bagging_predict(trees, row):
predictions = [predict(tree, row) for tree in trees]
return max(set(predictions), key=predictions.count)
# 创建随机森林
def random_forest(train, test, ratio, n_feature, max_depth, min_size, n_trees):
trees = []
for i in range(n_trees):
train = get_subsample(train, ratio)#从切割的数据集中选取子集
tree = build_tree(train, n_features, max_depth, min_size)
# print 'tree %d: '%i,tree
trees.append(tree)
# predict_values = [predict(trees,row) for row in test]
predict_values = [bagging_predict(trees, row) for row in test]
return predict_values
# 计算准确率
def accuracy(predict_values, actual):
correct = 0
for i in range(len(actual)):
if actual[i] == predict_values[i]:
correct += 1
return correct / float(len(actual))
if __name__ == '__main__':
seed(1)
dataSet = loadCSV('C:/Users/shadow/Desktop/组会/sonar-all-data.csv')
column_to_float(dataSet)#dataSet
n_folds = 5
max_depth = 16
min_size = 1
ratio = 1.0
# n_features=sqrt(len(dataSet)-1)
n_features = 15
n_trees = 11
folds = spiltDataSet(dataSet, n_folds)#先是切割数据集
scores = []
for fold in folds:
train_set = folds[
:] # 此处不能简单地用train_set=folds,这样用属于引用,那么当train_set的值改变的时候,folds的值也会改变,所以要用复制的形式。(L[:])能够复制序列,D.copy() 能够复制字典,list能够生成拷贝 list(L)
train_set.remove(fold)#选好训练集
# print len(folds)
train_set = sum(train_set, []) # 将多个fold列表组合成一个train_set列表
# print len(train_set)
test_set = []
for row in fold:
row_copy = list(row)
row_copy[-1] = None
test_set.append(row_copy)
# for row in test_set:
# print row[-1]
actual = [row[-1] for row in fold]
predict_values = random_forest(train_set, test_set, ratio, n_features, max_depth, min_size, n_trees)
accur = accuracy(predict_values, actual)
scores.append(accur)
print ('Trees is %d' % n_trees)
print ('scores:%s' % scores)
print ('mean score:%s' % (sum(scores) / float(len(scores))))

print result
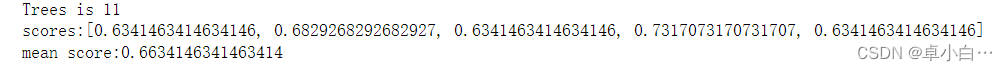
2. Comparison between Decision Tree and Random Forest
Implementation of a third-party machine learning library based on scikit-learn:
# -*- coding: utf-8 -*-
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.tree import DecisionTreeClassifier
##创建100个类共20000个样本,每个样本15个特征
X, y = make_blobs(n_samples=20000, n_features=15, centers=100, random_state=0)
## 决策树
clf1 = DecisionTreeClassifier(max_depth=None, min_samples_split=2, random_state=0)
scores1 = cross_val_score(clf1, X, y)
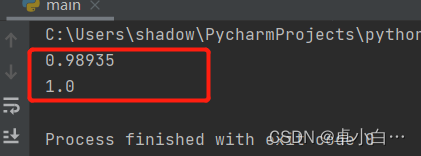
print(scores1.mean())
## 随机森林
clf2 = RandomForestClassifier(n_estimators=10, max_depth=None, min_samples_split=2, random_state=0)
scores2 = cross_val_score(clf2, X, y)
print(scores2.mean())
Print result:
Category of website: technical article > Blog
Author:mmm
link:http://www.pythonblackhole.com/blog/article/25321/6fade523d677f0727b35/
source:python black hole net
Please indicate the source for any form of reprinting. If any infringement is discovered, it will be held legally responsible.
name:
Comment content: (supports up to 255 characters)
no articles