
python ---->> Use urllib library to obtain network resources
posted on 2023-05-21 16:42 read(622) comment(0) like(29) collect(0)
My personal blog homepage: If '' can really escape 1️⃣ say 1️⃣ blog homepage
(1) about Python basic grammar learning ----> you can refer to my blog "I learn Python in VScode"
(2) pip is It is necessary to learn the importance of Python ---->> PiP in the process of learning the language of python
The Python urllib library is used to manipulate webpage URLs and crawl the content of webpages.
Use urllib library to get network resources
- what is url
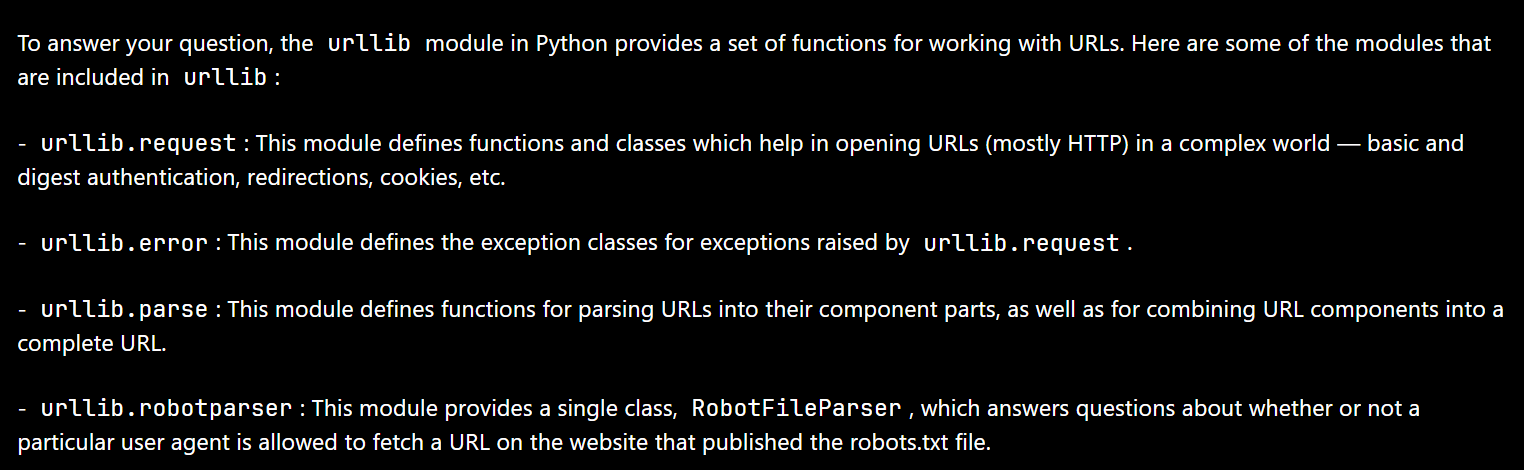
- Mainly included modules:
- [1] urllib.request (request module) ---> An extensible library for opening URLs
- 【2】- urllib.error (exception handling module): This module defines the exception class raised by urllib.request.
- [3] urllib.parse (url parsing module): This module defines a function that parses a URL into its components, and a function that combines URL components into a complete URL.
- [4] urllib.robotparser (robots.txt parsing module): This module provides a single class RobotFileParser, which is used to answer whether a specific user agent is allowed to obtain URLs on websites that publish robots.txt files.
- Use urllib library to get network resources
urllib is a module of Python that provides a series of modules for working with URLs. It can be used for tasks such as sending HTTP requests1 , handling cookies, and handling web sockets.
what is url
URL (foreign name: Uniform Resource Locator, Chinese name: Uniform Resource Locator), Uniform Resource Locator is a concise representation of the location and access method of resources that can be obtained from the Internet, and is the address of standard resources on the Internet . Every file on the Internet has a unique URL, which contains information indicating where the file is located and what the browser should do with it. It was originally invented by Tim Berners-Lee as an address for the World Wide Web.
Mainly included modules:
-
urllib.request (request module): This module defines functions and classes that help open URLs (mostly HTTP) in the complex world - basic and digest authentication, redirects, cookies, etc.
-
urllib.error (exception handling module): This module defines the exception classes raised by urllib.request.
-
urllib.parse (url parsing module): This module defines functions for parsing a URL into its constituent parts, and functions for combining URL components into a complete URL.
-
urllib.robotparser (robots.txt parsing module): This module provides a single class RobotFileParser for answering whether a particular user agent is allowed to fetch URLs on sites that publish robots.txt files.
[1] urllib.request (request module) —> an extensible library for opening URLs
(1)urllib.request.urlopen
The main job of the urllib.request.urlopen() function is to open the specified URL and retrieve the response.
function prototype
The urlopen() method not only supports the HTTP protocol, but also supports other common protocols,
- Such as FTP, SMTP, and HTTPS.
- Telnet
- File / URL
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
- url:要打开的URL。
- data:这是一个可选参数,用于指定要发送到服务器的数据。
如果不提供此参数,则请求将是GET请求。如果提供了它,则请求将是POST请求。
- timeout:这是一个可选参数,用于指定请求的超时时间(以秒为单位)。
如果服务器在此时间内没有响应,则会引发timeout异常。
- cafile:这是一个可选参数,用于指定包含用于SSL验证的CA证书的文件的路径。
- capath:这是一个可选参数,用于指定包含用于SSL验证的CA证书的目录的路径。
- cadefault:这是一个可选参数,用于指定是否使用系统的默认CA证书进行SSL验证。
- context:这是一个可选参数,用于指定用于请求的SSL上下文。
example:
import urllib.request
response = urllib.request.urlopen('**你的网站**')
html = response.read()
print(html)
The urllib.request.urlopen function is used to open the URL you need to know about the website .
Then, use the read method to read the contents of the URL into the variable html. (The return value of the response page obtained by the method. Read the content in the opened URL and return the byte string (bytes).)
Finally, use the print function to print the content of the html to the console.
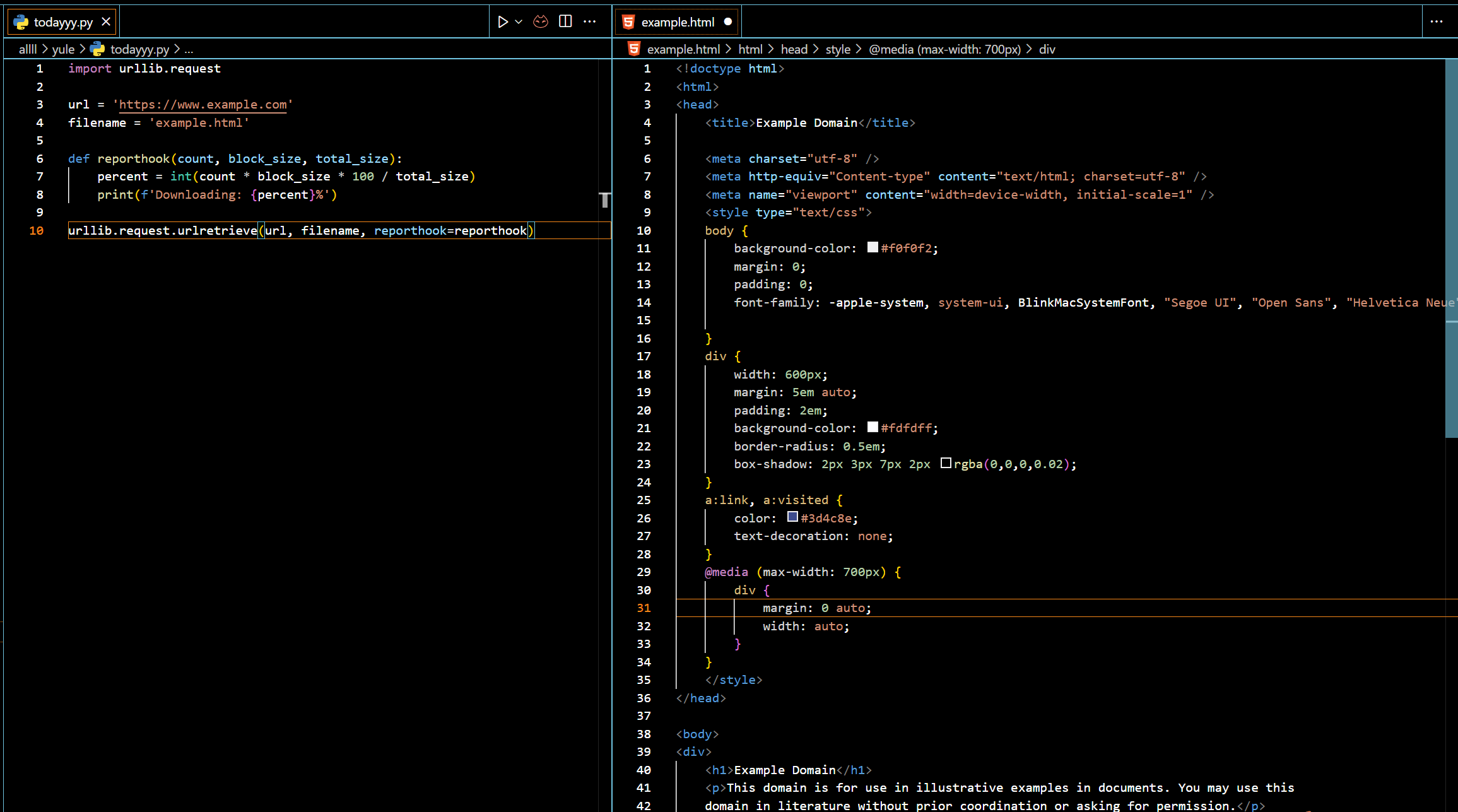
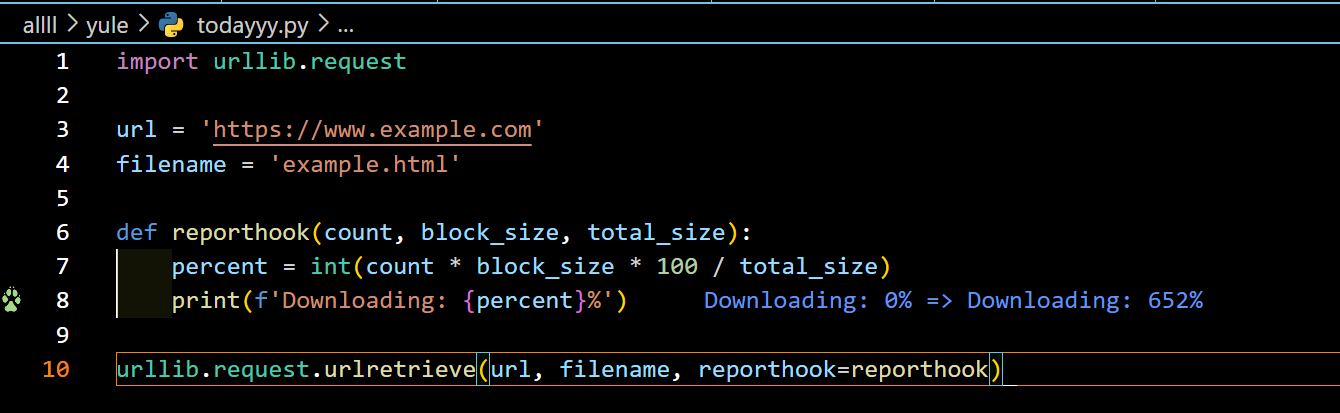
(2) urllib.request.urlretrieve —> This function retrieves the content of the specified URL and saves it to a local file.
urllib.request.urlretrieve(url, [filename=None, ]reporthook=None, data=None)
-
url: The URL to retrieve.
-
filename: The local filename to save the content to. If not specified, the function will try to guess the filename from the URL and save it in the current working directory.
-
reporthook: optional parameter, used to specify a callback function, which will be called during the retrieval process to display progress information.
example
If a filename parameter is passed, and the URL points to a local resource, the result is copied from the local file to the new file.
The urllib.request.urlretrieve function returns a tuple containing the path to the newly created data file and the resulting HTTPMessage object.
【2】- urllib.error (exception handling module): This module defines the exception class raised by urllib.request.
urllib.error.URLError(reason, *args): 这是所有在URL处理期间发生的异常的基类。当无法打开或检索URL时,会引发此异常。reason参数是一个字符串,用于描述错误的原因。args参数是一个元组,包含其他与错误相关的信息。
urllib.error.HTTPError(url, code, msg, hdrs, fp):这是URLError的子类,当发生HTTP错误时引发。它包含有关HTTP错误代码和原因的信息。url参数是引发错误的URL,code参数是HTTP错误代码,msg参数是HTTP错误原因短语,hdrs参数是HTTP响应头,fp参数是一个文件对象,用于读取错误响应的主体。
urllib.error.ContentTooShortError(msg, content): 这是URLError的子类,当下载的内容比预期的短时引发。msg参数是一个字符串,用于描述错误的原因。content参数是一个字节串,包含下载的内容。
# 导入urllib.error模块:
import urllib.error
【3】urllib.parse(url解析模块):该模块定义了将URL解析为其组成部分的函数,以及将URL组件组合成完整URL的函数。
- urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True) -> ParseResult: 将URL解析为其组件,并返回一个包含解析结果的ParseResult对象。
- urllib.parse.urlunparse(components)-> str: 接受URL组件的元组并返回完整的URL字符串。
- urllib.parse.urlencode(query, doseq=False, safe='', encoding=None, errors=None, quote_via=quote_plus) -> str: 接受查询参数的字典并返回URL编码的字符串。
- urllib.parse.parse_qs(qs, keep_blank_values=False, strict_parsing=False, encoding='utf-8', errors='replace', max_num_fields=None) -> Dict[str, Union[str, List[str]]]: 接受URL编码的查询字符串并返回查询参数的字典。
【4】 urllib.robotparser(robots.txt解析模块):该模块提供了一个单一的类RobotFileParser,用于回答特定用户代理是否被允许在发布robots.txt文件的网站上获取URL。
- urllib.robotparser.RobotFileParser(url=''):Creates a new RobotFileParser object that can parse robots.txt files for the specified URL.
- urllib.robotparser.set_url(url):Sets the URL of the robots.txt file to parse.
- urllib.robotparser.read():Read the robots.txt file from the specified URL and parse its content.
- urllib.robotparser.can_fetch(useragent, url):Checks whether the specified user agent can access the specified URL. Return True if it can; otherwise return False.
- urllib.robotparser.mtime():Returns the timestamp of the last time the robots.txt file was read.
- urllib.robotparser.modified():Returns whether the robots.txt file has been modified.
Use urllib library to get network resources
Of course, obtaining the desired network resources is the first priority for us to study this article.
You can refer to this blog: HTML that crawlers want
An HTTP request refers to the process in which a client sends a request to a server and receives a response from the server. ↩︎
Category of website: technical article > Blog
Author:mmm
link:http://www.pythonblackhole.com/blog/article/25291/dc54e070d47bde7a3fcf/
source:python black hole net
Please indicate the source for any form of reprinting. If any infringement is discovered, it will be held legally responsible.
name:
Comment content: (supports up to 255 characters)
no articles