
requests库的使用(一篇就够了)
posted on 2023-06-06 12:21 read(252) comment(0) like(4) collect(1)
The urllib library is cumbersome to use. For example, when dealing with webpage verification and Cookies, you need to write Opener and Handler to handle it. In order to realize these operations more conveniently, there is a more powerful requests library.
Installation of the request library
requests is a third-party library, and Python is not built-in, so we need to install it manually.
1. Related links
-
GitHub:https://github.com/psf/requests
-
PyPI:https://pypi.org/project/requests/
-
Official documentation: https://docs.python-requests.org/en/latest/
-
Chinese documentation: https://docs.python-requests.org/zh_CN/latest/user/quickstart.html
2. Install via pip
Whether it is Windows, Linux or Mac, requests can be installed through pip, a package management tool. Run the following command on the command line interface to complete the installation of the requests library:
pip3 install requests
In addition to installing through pip, it can also be installed through wheel or source code, which will not be described here.
3. Verify the installation
You can test whether requests is installed successfully by importing the import library on the command line.
 The import library is successful, indicating that the requests installation is successful.
The import library is successful, indicating that the requests installation is successful.
basic usage
The following example sends a get request using the get( ) method in the requests library.
#导入requests库
import requests
#发送一个get请求并得到响应
r = requests.get('https://www.baidu.com')
#查看响应对象的类型
print(type(r))
#查看响应状态码
print(r.status_code)
#查看响应内容的类型
print(type(r.text))
#查看响应的内容
print(r.text)
#查看cookies
print(r.cookies)
Here, the get( ) method is called to implement the same operation as urlopen( ), and a response object is returned as a result, and then the response object type, status code, response body content type, response body content, and Cookies are respectively output. From the running results, we can know that the type of the response object is requests.models.Response, the type of the response body content is str, and the type of Cookies is RequestCookieJar. If you want to send other types of requests, just call their corresponding methods directly:
r = requests.post('https://www.baidu.com')
r = requests.put('https://www.baidu.com')
r = requests.delete('https://www.baidu.com')
r = requests.head('https://www.baidu.com')
r = requests.options('https://www.baidu.com')
GET request
Build a GET request and request http://httpbin.org/get (the website will judge that if the client initiates a GET request, it will return the corresponding information)
import requests
r = requests.get('http://httpbin.org/get')
print(r.text)

1) If you want to add request parameters, such as adding two request parameters, where the value of name is germey and the value of age is 20. Although it can be written as follows:
r = requests.get('http://httpbin.org/get?name=germey&age=20')
But a better way of writing is as follows:
import requests
data = {
'name':'germey',
'age':22
}
r = requests.get('http://httpbin.org/get',params=data)
print(r.text)

It can be seen from the running results that the requested URL is finally constructed as "http://httpbin.org/get?name=germey&age=20".
2) The type of the returned content of the webpage is str type, if it conforms to the JSON format, you can use the json( ) method to convert it into a dictionary type for easy parsing.
import requests
r = requests.get('http://httpbin.org/get')
#str类型
print(type(r.text))
#返回响应内容的字典形式
print(r.json())
#dict类型
print(type(r.json()))
However, it should be noted that if the returned content is not in JSON format, an error will occur when calling the json() method, and a json.decoder.JSONDecodeError exception will be thrown.
POST request
1) Send a POST request.
import requests
r = requests.post('http://httpbin.org/post')
print(r.text)
2) Send a POST request with request parameters.
import requests
data = {
"name":"germey",
"age":"22"
}
r = requests.post('http://httpbin.org/post',data=data)
print(r.text)

In the POST request method, the form part is the request parameter.
set request header
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0',
'my-test':'Hello'
}
r = requests.get('http://httpbin.org/get',headers=headers)
print(r.text)

response
1) After sending the request, a response is returned, which has many attributes, and the status code, response header, cookies, response content, etc. can be obtained through its attributes. as follows:
import requests
r = requests.get('https://www.baidu.com/')
#响应内容(str类型)
print(type(r.text),r.text)
#响应内容(bytes类型)
print(type(r.content),r.content)
#状态码
print(type(r.status_code),r.status_code)
#响应头
print(type(r.headers),r.headers)
#Cookies
print(type(r.cookies),r.cookies)
#URL
print(type(r.url),r.url)
#请求历史
print(type(r.history),r.history)

2) The status code is often used to determine whether the request is successful. In addition to the status code provided by HTTP, the requests library also provides a built-in status code query object called requests.codes. In fact, both are equivalent. Examples are as follows:
import requests
r = requests.get('https://www.baidu.com/')
if not r.status_code==requests.codes.ok:
print('Request Fail')
else:
print('Request Successfully')
The status codes owned by the requests.codes object are as follows:
#信息性状态码
100:('continue',),
101:('switching_protocols',),
102:('processing',),
103:('checkpoint',),
122:('uri_too_long','request_uri_too_long'),
#成功状态码
200:('ok','okay','all_ok','all_okay','all_good','\\o/','√'),
201:('created',),
202:('accepted',),
203:('non_authoritative_info','non_authoritative_information'),
204:('no_content',),
205:('reset_content','reset'),
206:('partial_content','partial'),
207:('multi_status','multiple_status','multi_stati','multiple_stati'),
208:('already_reported',),
226:('im_used',),
#重定向状态码
300:('multiple_choices',),
301:('moved_permanently','moved','\\o-'),
302:('found',),
303:('see_other','other'),
304:('not_modified',),
305:('user_proxy',),
306:('switch_proxy',),
307:('temporary_redirect','temporary_moved','temporary'),
308:('permanent_redirect',),
#客户端请求错误
400:('bad_request','bad'),
401:('unauthorized',),
402:('payment_required','payment'),
403:('forbiddent',),
404:('not_found','-o-'),
405:('method_not_allowed','not_allowed'),
406:('not_acceptable',),
407:('proxy_authentication_required','proxy_auth','proxy_authentication'),
408:('request_timeout','timeout'),
409:('conflict',),
410:('gone',),
411:('length_required',),
412:('precondition_failed','precondition'),
413:('request_entity_too_large',),
414:('request_uri_too_large',),
415:('unsupported_media_type','unsupported_media','media_type'),
416:('request_range_not_satisfiable','requested_range','range_not_satisfiable'),
417:('expectation_failed',),
418:('im_a_teapot','teapot','i_am_a_teapot'),
421:('misdirected_request',),
422:('unprocessable_entity','unprocessable'),
423:('locked'),
424:('failed_dependency','dependency'),
425:('unordered_collection','unordered'),
426:('upgrade_required','upgrade'),
428:('precondition_required','precondition'),
429:('too_many_requests','too_many'),
431:('header_fields_too_large','fields_too_large'),
444:('no_response','none'),
449:('retry_with','retry'),
450:('blocked_by_windows_parental_controls','parental_controls'),
451:('unavailable_for_legal_reasons','legal_reasons'),
499:('client_closed_request',),
#服务端错误状态码
500:('internal_server_error','server_error','/o\\','×')
501:('not_implemented',),
502:('bad_gateway',),
503:('service_unavailable','unavailable'),
504:('gateway_timeout',),
505:('http_version_not_supported','http_version'),
506:('variant_also_negotiates',),
507:('insufficient_storage',),
509:('bandwidth_limit_exceeded','bandwith'),
510:('not_extended',),
511:('network_authentication_required','network_auth','network_authentication')
crawl binary data
Files such as pictures, audio, and video are essentially composed of binary codes, so if you want to crawl them, you must get their binary codes. Take crawling Baidu's site icon (the small icon on the tab) as an example:
import requests
#向资源URL发送一个GET请求
r = requests.get('https://www.baidu.com/favicon.ico')
with open('favicon.ico','wb') as f:
f.write(r.content)
Use the open( ) method, its first parameter is to save the file name (with a path), and the second parameter indicates to write data in binary form. After running, you can find the saved icon named favicon.ico in the current directory. Similarly, audio and video can also be obtained in this way.
File Upload
requests can simulate submitting some data. If a website needs to upload files, we can also achieve it.
import requests
#以二进制方式读取当前目录下的favicon.ico文件,并将其赋给file
files = {'file':open('favicon.ico','rb')}
#进行上传
r = requests.post('http://httpbin.org/post',files=files)
print(r.text)
Handling Cookies
Using urllib to handle Cookies is more complicated, but using requests to handle Cookies is very simple.
1) Obtain Cookies.
import requests
r = requests.get('https://www.baidu.com')
#打印Cookies对象
print(r.cookies)
#遍历Cookies
for key,value in r.cookies.items():
print(key+'='+value)
Cookies can be obtained by calling the cookies property of the response object, which is an object of RequestCookiesJar type, and then use the items() method to convert it into a list of tuples, and traverse and output the name and value of each cookie.
2) Use Cookies to maintain login status. Take Zhihu as an example, first log in Zhihu, enter a page that can only be accessed after logging in, and copy the Cookies in the Headers in the browser developer tools (sometimes the directly copied Cookies contain ellipsis, which will cause the program If there is an error, you can enter document.cookie under the Console item to get the complete cookie), use it in the program, set it in the Headers, and then send the request.
import requests
headers = {
'Cookie':'_zap=616ef976-1fdb-4b8c-a3cb-9327ff629ff1; _xsrf=0CCNkbCLtTAlz5BfwhMHBHJWW791ZkK6; d_c0=\"AKBQTnFIRhSPTpoYIf6mUxSic2UjzSp4BYM=|1641093994\"; __snaker__id=mMv5F3gmBHIC9jJg; gdxidpyhxdE=E%2BNK7sMAt0%2F3aZ5Ke%2FSRfBRK7B1QBmCtaOwrqJm%2F1ONP3VPItkrXCcMiAX3%2FIsSxUwudQPyuDGO%2BlHGPvNqGqO9bX1%2B58o7wmf%2FZewh8xSPg%2FH3T2HoWsrs7ZhsSGND0C0la%2BXkLIIG5XXV85PxV5g99d%5CMph%2BbkX1JQBGhDnL3N0zRf%3A1641094897088; _9755xjdesxxd_=32; YD00517437729195%3AWM_NI=rMeMx2d5Yt3mg0yHPvuPGTjPnGtjL%2Bn%2FPSBnVn%2FHFAVZnIEABUIPITBdsHmMX1iCHfKauO4qhW%2Bi5bTy12Cg91vrxMPgOHtnaAylN8zk7MFpoTr%2FTeKVo3%2FKSSM6T5cNSGE%3D; YD00517437729195%3AWM_NIKE=9ca17ae2e6ffcda170e2e6ee8bea40f8e7a4b2cf69b3b48fb7c54b979b8fbaf17e93909b91fb338ebaaeadec2af0fea7c3b92ab293abaefb3aa8eb9795b267a5f0b7a9d37eb79089b5e95cae99bc8bcf21aef1a0b4c16696b2e1a9c54b9686a2aac84b828b87b1cc6082bcbda9f0479cefa7a4cb6e89bfbbb0b77bac89e58ab86a98a7ffd3c26dfbefba93fb4794b981a9f766a39fb78dcd34bab5f9aec57cad8cbed0d76f898aa1d4ae41918d83d7d73fa1929da8c837e2a3; YD00517437729195%3AWM_TID=Kji43bLtZbRAAAVABFMu4upmK4C%2BEGQH; KLBRSID=9d75f80756f65c61b0a50d80b4ca9b13|1641268679|1641267986; tst=r; NOT_UNREGISTER_WAITING=1; SESSIONID=lbWS7Y8pmp5qM1DErkXJCahgQwwyl79eT8XAOC6qC7A; JOID=V1wXAUwzD9BQH284PTQMxsZMqrkrXmuHBio3Bk1cfuMhV1x9fiHKBjYcaD44XxiWm2kKD5TjJvk-7iTeM3d6aYA=; osd=VVoQAk0xCddTHm0-OjcNxMBLqbgpWGyEBygxAU5dfOUmVF1_eCbJBzQabz05XR6RmGgICZPgJ_s46SffMXF9aoE=; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1640500881,1641093994,1641267987; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1641268678',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0',
'Host':'www.zhihu.com'
}
r = requests.get('https://www.zhihu.com/people/xing-fu-shi-fen-dou-chu-lai-de-65-18',headers=headers)
print(r.text)
After running, the result contains the content after login, indicating that the login status is obtained successfully.
3) It can also be set through the cookies parameter, but in this way, the RequestCookieJar object needs to be constructed, and the following cookies need to be divided, which is relatively cumbersome, but the effect is the same.
import requests
cookies ='_zap=616ef976-1fdb-4b8c-a3cb-9327ff629ff1; _xsrf=0CCNkbCLtTAlz5BfwhMHBHJWW791ZkK6; d_c0=\"AKBQTnFIRhSPTpoYIf6mUxSic2UjzSp4BYM=|1641093994\"; __snaker__id=mMv5F3gmBHIC9jJg; gdxidpyhxdE=E%2BNK7sMAt0%2F3aZ5Ke%2FSRfBRK7B1QBmCtaOwrqJm%2F1ONP3VPItkrXCcMiAX3%2FIsSxUwudQPyuDGO%2BlHGPvNqGqO9bX1%2B58o7wmf%2FZewh8xSPg%2FH3T2HoWsrs7ZhsSGND0C0la%2BXkLIIG5XXV85PxV5g99d%5CMph%2BbkX1JQBGhDnL3N0zRf%3A1641094897088; _9755xjdesxxd_=32; YD00517437729195%3AWM_NI=rMeMx2d5Yt3mg0yHPvuPGTjPnGtjL%2Bn%2FPSBnVn%2FHFAVZnIEABUIPITBdsHmMX1iCHfKauO4qhW%2Bi5bTy12Cg91vrxMPgOHtnaAylN8zk7MFpoTr%2FTeKVo3%2FKSSM6T5cNSGE%3D; YD00517437729195%3AWM_NIKE=9ca17ae2e6ffcda170e2e6ee8bea40f8e7a4b2cf69b3b48fb7c54b979b8fbaf17e93909b91fb338ebaaeadec2af0fea7c3b92ab293abaefb3aa8eb9795b267a5f0b7a9d37eb79089b5e95cae99bc8bcf21aef1a0b4c16696b2e1a9c54b9686a2aac84b828b87b1cc6082bcbda9f0479cefa7a4cb6e89bfbbb0b77bac89e58ab86a98a7ffd3c26dfbefba93fb4794b981a9f766a39fb78dcd34bab5f9aec57cad8cbed0d76f898aa1d4ae41918d83d7d73fa1929da8c837e2a3; YD00517437729195%3AWM_TID=Kji43bLtZbRAAAVABFMu4upmK4C%2BEGQH; KLBRSID=9d75f80756f65c61b0a50d80b4ca9b13|1641268679|1641267986; tst=r; NOT_UNREGISTER_WAITING=1; SESSIONID=lbWS7Y8pmp5qM1DErkXJCahgQwwyl79eT8XAOC6qC7A; JOID=V1wXAUwzD9BQH284PTQMxsZMqrkrXmuHBio3Bk1cfuMhV1x9fiHKBjYcaD44XxiWm2kKD5TjJvk-7iTeM3d6aYA=; osd=VVoQAk0xCddTHm0-OjcNxMBLqbgpWGyEBygxAU5dfOUmVF1_eCbJBzQabz05XR6RmGgICZPgJ_s46SffMXF9aoE=; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1640500881,1641093994,1641267987; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1641268678'
jar = requests.cookies.RequestsCookieJar()
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0',
'Host':'www.zhihu.com'
}
for cookie in cookies.split(';'):
key,value = cookie.split('=',1)
jar.set(key,value)
r = requests.get('https://www.zhihu.com/people/xing-fu-shi-fen-dou-chu-lai-de-65-18',headers=headers)
print(r.text)
session maintenance
By calling methods such as get( ) or post( ), you can simulate web page requests, but this is actually equivalent to different sessions, that is to say, you use two browsers to open different pages. If the first request uses the post( ) method to log in to the website, and the second time you want to get your own personal information after successful login, you use the get( ) method to get the requested personal information again. In fact, this is equivalent to opening two browser, so personal information cannot be obtained successfully. For this reason, session maintenance is required. You can set the same Cookies in two requests, but this is very cumbersome, and a session can be easily maintained through the Session class.
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)
First open a session through requests, and then send a get request through the session, which is used to set the parameter number in cookies, the parameter value is 123456789; then use this to initiate a get request to get Cookies, and then print fetched content.

fetched successfully.
SSL certificate verification
requests also provides a certificate verification function. When an HTTP request is sent, it will check the SSL certificate. We can use the verify parameter to control whether to check the SSL certificate.
1) When requesting an HTTPS website, if the certificate of the website is not trusted by the CA institution, the program will make an error, prompting an SSL certificate verification error. For this, just set the verify parameter to False. as follows:
import requests
resposne = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
It is also possible to specify a local certificate to be used as the client certificate, which can be a single file (containing key and certificate) or a tuple containing paths to two files.
import requests
#本地需要有crt和key文件(key必须是解密状态,加密状态的key是不支持的),并指定它们的路径,
response = requests.get('https://www.12306.cn',cert('/path/server.crt','/path/key'))
print(response.status_code)
2) When requesting an HTTPS website whose SSL certificate is not recognized by the CA institution, although the verify parameter is set to False, a warning may be generated when the program runs. In the warning, it is recommended that we specify a certificate for it, which can be shielded by setting the ignore warning This warning:
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
或者通过捕获警告到日志的方式忽略警告:
import logging
import requests
logging.captureWarnings(True)
response = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
proxy settings
For some websites, the content can be obtained normally after requesting several times during the test. However, once large-scale and frequent crawling starts, the website may pop up a verification code, or jump to the login verification page, or even directly block the client's IP, resulting in inability to access for a certain period of time. In order to prevent this, we need to use proxies to solve this problem, which requires the proxies parameter.
1) Set proxy
import requests
proxies = {
#该代理服务器在免费代理网站上得到的,这样的网站有很多
'http': 'http://161.35.4.201:80',
'https': 'https://161.35.4.201:80'
}
try:
response = requests.get('http://httpbin.org/get', proxies=proxies)
print(response.text)
except requests.exceptions.ConnectionError as e:
print('Error', e.args)

It can be found that we are using a proxy server for access.
2)如果代理需要使用HTTP Basic Auth,可以使用类似http://user:password@host:port这样的语法来设置代理。
import requests
proxies = {
"http":"http://user:password@161.35.4.201:80"
}
r = requests.get("https://www.taobao.com",proxies=proxies)
print(r.text)
3)除了基本的HTTP代理外,requests还支持SOCKS协议的代理。首先需要安装socks这个库:
pip3 install 'requests[socks]'
import requests
proxies = {
'http':'socks5://user:password@host:port',
'https':'socks5://user:password@host:port'
}
request.get('https://www.taobao.com',proxies=proxies)
然后就可以使用SOCKS协议代理了
import requests
proxies = {
'http':'socks5://user:password@host:port',
'https':'socks5://user:password@host:port'
}
requests.get('https://www.taobao.com',proxies=proxies)
超时设置
在本机网络状况不好或者服务器网络响应太慢甚至无响应时,我们可能会等待特别久的时间才可能收到响应,甚至到最后收不到响应而报错。为了应对这种情况,应设置一个超时时间,这个时间是计算机发出请求到服务器返回响应的时间,如果请求超过了这个超时时间还没有得到响应,就抛出错误。这就需要使用timeout参数实现,单位为秒。
1)指定请求总的超时时间
import requests
#向淘宝发出请求,如果1秒内没有得到响应,则抛出错误
r = requests.get('https://www.taobao.com',timeout=1)
print(r.status_code)
2)分别指定超时时间。实际上,请求分为两个阶段:连接(connect)和读取(read)。如果给timeout参数指定一个整数值,则超时时 间是这两个阶段的总和;如果要分别指定,就可以传入一个元组,连接超时时间和读取超时时间:
import requests
#向淘宝发出请求,如果连接阶段5秒内没有得到响应或读取阶段30秒内没有得到响应,则抛出错误
r = requests.get('https://www.taobao.com',timeout=(5,30))
print(r.status_code)
3)如果想永久等待,可以直接timeout设置为None,或者不设置timeout参数,因为它的默认值就是None。
import requests
#向淘宝发出请求,如果连接阶段5秒内没有得到响应或读取阶段30秒内没有得到响应,则抛出错误
r = requests.get('https://www.taobao.com',timeout=None))
print(r.status_code)
身份验证
访问某网站时,可能会遇到如下的验证页面:
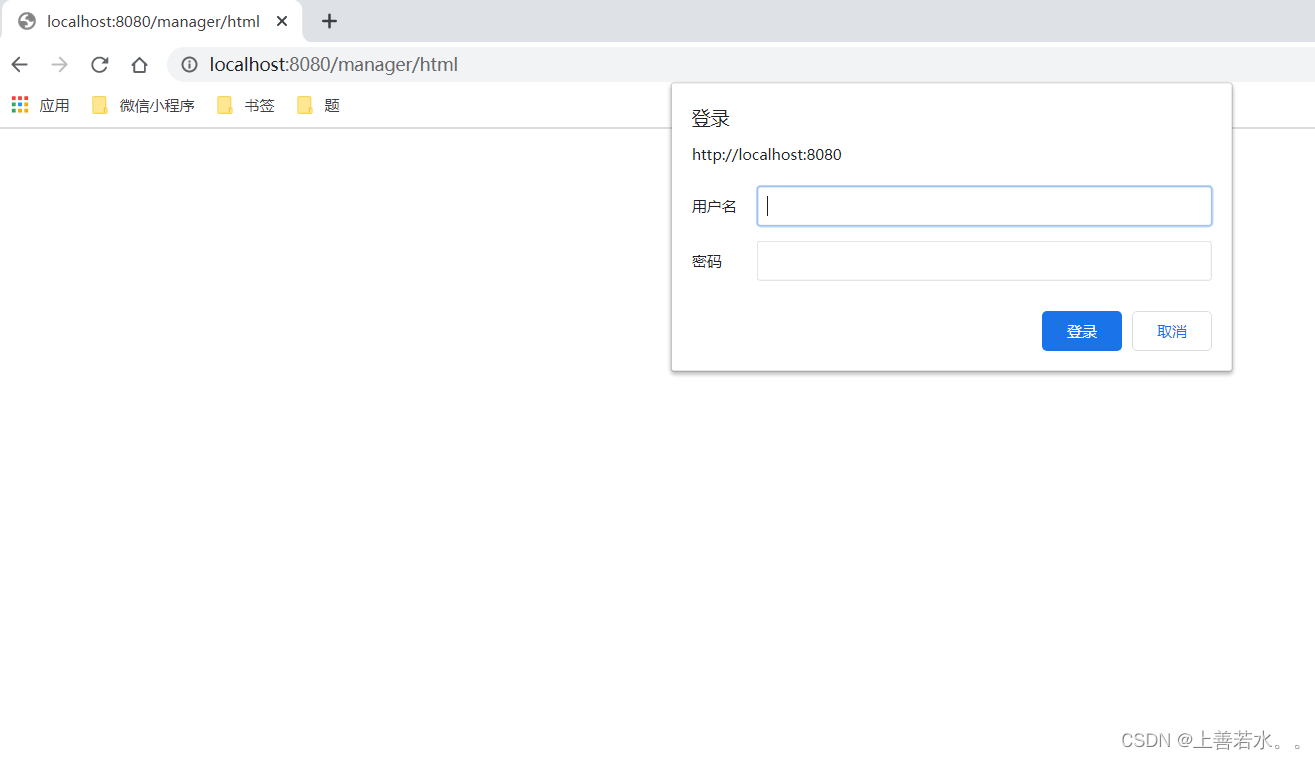
1)此时可以使用requests自带的身份验证功能,通过HTTPBasicAuth类实现。
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('http://localhost:8080/manager/html',auth=HTTPBasicAuth('admin','123456'))
print(r.status_code)
如果用户名和密码正确的话,返回200状态码;如果不正确,则返回401状态码。也可以不使用HTTPBasicAuth类,而是直接传入一个 元组,它会默认使用HTTPBasicAuth这个类来验证。
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('http://localhost:8080/manager/html',auth=('admin','123456'))
print(r.status_code)
2)requests还提供了其他验证方式,如OAuth验证,不过需要安装oauth包,安装命令如下:
pip3 install requests_oauthlib
使用OAuth验证的方法如下:
import requests
from requests_oauthlib import OAuth1
url = 'https://api.twitter.com/1.1/account/verify_credentials.json'
auth = OAuth1("YOUR_APP_KEY","YOUR_APP_SECRET","USER_OAUTH_TOKEN","USER_OAUTH_TOKEN_SECRET")
requests.get(url,auth=auth)
Prepared Request
在学习urllib库时,发送请求如果需要设置请求头,需要通过一个Request对象来表示。在requests库中,存在一个与之类似的类,称为Prepared Request。
from requests import Request,Session
url = 'http://httpbin.org/post'
data = {
'name':'germey'
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0'
}
s = Session()
req = Request('POST',url,data=data,headers=headers)
prepped = s.prepare_request(req)
r = s.send(prepped)
print(r.text)
The Request is introduced here, and then a Request object is constructed with the url, data and headers parameters. At this time, it is necessary to call the prepare_request( ) method of the Session to convert it into a Prepared Request object, and then call the send( ) method to send it. The advantage of this is that you can use Request to treat requests as independent objects, which is very convenient for queue scheduling, and will be used to construct a Request queue later.
Category of website: technical article > Blog
Author:Believesinkinto
link:http://www.pythonblackhole.com/blog/article/80678/4fd7cf31d2e56490340d/
source:python black hole net
Please indicate the source for any form of reprinting. If any infringement is discovered, it will be held legally responsible.
name:
Comment content: (supports up to 255 characters)
no articles