
Gesture recognition of computer vision (principle + code practice)
posted on 2023-06-06 11:11 read(513) comment(0) like(15) collect(0)

1. The overall process of gesture recognition

2. Human Body Segmentation
•The methods used for human body segmentation can be roughly divided into human skeleton key point detection and semantic segmentation. Here we mainly analyze the key point detection of human skeleton related to posture. The output of human skeleton key point detection is the skeleton information of the human body, which is generally used as the basic part of human body pose recognition, mainly used for segmentation and alignment. The general implementation process is:

3. Human gesture recognition


4. Human skeleton key point detection
•Mainly detect the key point information of the human body, such as joints, facial features, etc., and describe the human skeleton information through key points, which are often used as basic components for gesture recognition and behavior analysis, as shown in the following figure:

Divided into two modes:
The top-down key point is that the target detects the human body frame, and then performs key point detection
The bottom-up (BottomUp) human skeleton key point detection algorithm mainly includes two parts: key point detection and key point clustering connection. The purpose of key point detection is to detect all key points of all people in the picture. After the key points are detected, these key points need to be clustered, and the different key points of each person are connected together, so as to connect

Take openpose as an example:
• The detection process of openpose is:
•1) Calculate all key points (head, shoulders, elbows, wrists...)
• 2) Calculate all associated regions
•3) Carry out vector connection according to the key points and associated areas, the key points and associated areas obtained in the first two steps, and then need to connect the key points according to the associated areas to form the real bone structure of the human body. The author proposes a spanning tree diagram of individual poses with a minimum number of edges (using bipartite graph + Hungarian algorithm, etc.), which greatly reduces complexity and improves real-time performance while ensuring good accuracy. When pairing the key points, it is necessary to try each pair of points and then find the optimal division and combination structure.
5. 2D+ human bone key point detection
• DensePose-RCNN uses the RCNN structure of the pyramid network (FPN) feature, and the regional feature aggregation method ROIalign pooling to obtain the dense partial labels and coordinates in each selected area. Project the surface image data of the person in the 2D image onto the surface of the 3D human body, divide the 3D surface model of the human body into 24 parts, and then construct a UV coordinate system for each part, and map each point of the human body part on the 2D image mapped to the corresponding 3D surface part. It is also possible to paste the 3D model on the image after estimating the UV of the human body in the image, converting the space coordinates into UV coordinates through transformation.
•DensePose draws on the structure of Mask-RCNN, with features of FeaturePyramid Network (FPN), and ROI-Align pooling. The overall process is as follows: First, use Faster-RCNN to obtain the boundingbox of the character area, then use the CNN network module to divide into blocks, and then use the CNN network model to process each block, and finally get the heat map IVU of the target.
6. Realization of key point detection of 3D human skeleton

Seven, commonly used algorithms
• DensePose
• OpenPose
•Realtime Multi-Person Pose Estimation
•AlphaPose(RMPE)
•Human Body Pose Estimation
• DeepPose
•Mediapipe(MoveNet)
1. RMPE algorithm (top-down)


First perform pedestrian detection , get the bounding box, and then detect the key points of the human body in each bounding box, and connect them into a human figure. The disadvantage is that it is too much affected by the detection box, missed detection, false detection, IOU size, etc. will affect the result.
2. Mediapipe (bottom-up)
• MoveNet model: a lightweight pose estimation model launched by Google in May 2021
•The bottom-up model, this paradigm is generally used in multi-person pose estimation, and more specifically, MoveNet is a bottom-up single-person pose estimation model. From MoveNet's technical blog sharing, it has achieved an excellent balance between the two paradigms, which not only avoids training a det model separately, but also preserves the accuracy advantage of single-person pose estimation as much as possible.
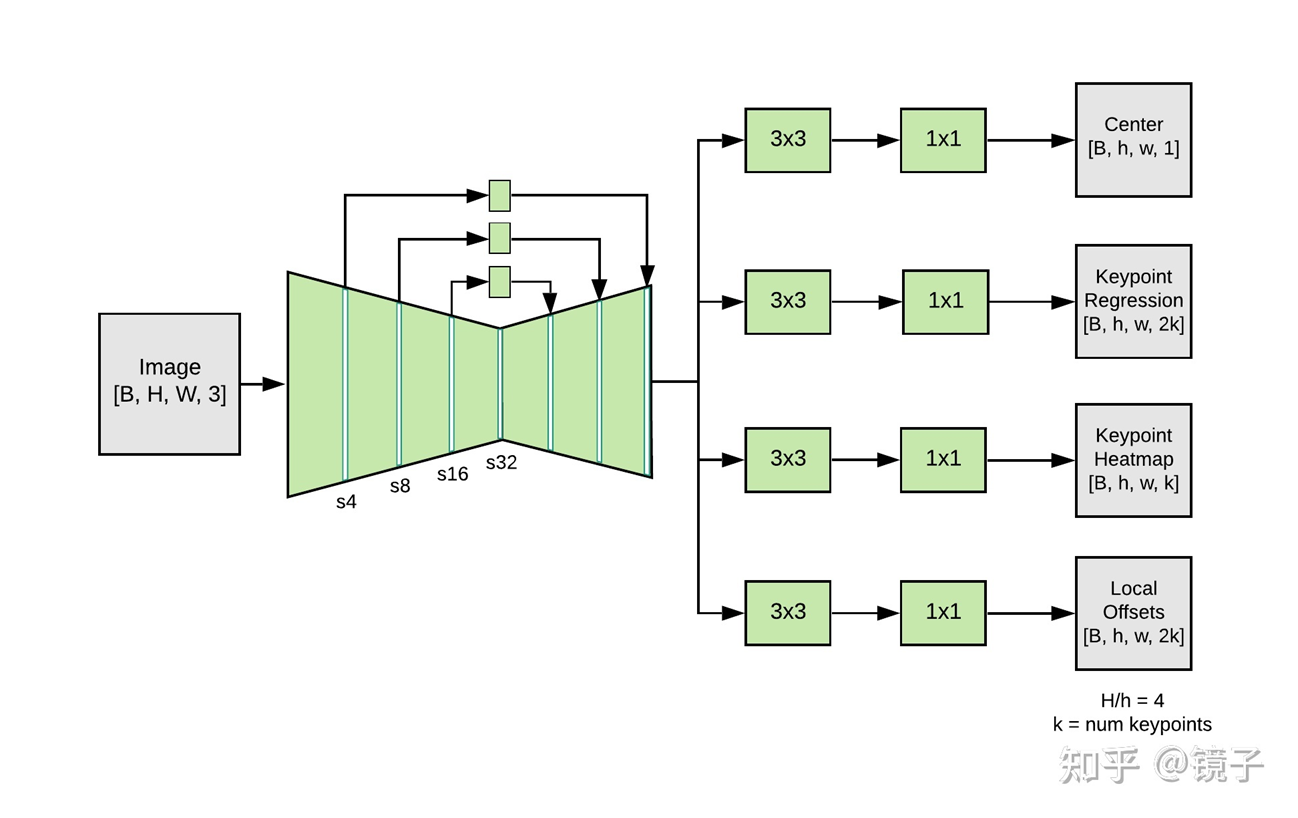
Fast downsampling: Compress the image size as fast as possible to reduce the overall calculation load
Residual structure: Obtain shallow features and gradients, to a certain extent make up for some problems caused by fast downsampling (downsampling is too fast and the information loss is too serious, the model has no time to learn some advanced and meaningful semantic features), and strengthen the features spatial information
Parameters are concentrated on the main branch: the parameters and calculations on the residual branch should be kept as small as possible, and the relatively poor computing power should be used on the main branch
output:
CenterHeatmap[B, 1, H, W]: Predict the geometric center of each person, mainly used for presence detection, and use an anchor point on the Heatmap to replace the bbox of the target detection
KeypointRegression[B, 2K, H, W]: Regression of 17 joint point coordinates based on the center point
KeypointHeatmap[B, K, H, W]: Each type of key point is detected using a Heatmap, which means that multiple Gaussian kernels will appear in this Heatmap in a multi-person scene
OffsetRegression[B, 2K, H, W]: Regress the offset value of each Gaussian kernel center in the Keypoint Heatmap and the real coordinates, which is used to eliminate the quantization error of the Heatmap method
Eight, code operation
The mediapipe algorithm is used for a simple demonstration:
- import cv2
- import mediapipe as mp
-
- import time #计算fps值
- #两个初始化
- mpPose = mp.solutions.pose
- pose = mpPose.Pose()
- #初始化画图工具
- mpDraw = mp.solutions.drawing_utils
-
- #调用摄像头,在同级目录下新建Videos文件夹,然后在里面放一些MP4文件,方便读取
- cap = cv2.VideoCapture('只因.mp4')
- #计算pfs值需要用到的变量,先初始化以一下
- pTime = 0
-
- while True:
- #读取图像
- success, img = cap.read()
- #转换为RGB格式,因为Pose类智能处理RGB格式,读取的图像格式是BGR格式
- imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
- #处理一下图像
- results = pose.process(imgRGB)
- # print(results.pose_landmarks)
- #检测到人体的话:
- if results.pose_landmarks:
- #使用mpDraw来刻画人体关键点并连接起来
- mpDraw.draw_landmarks(img, results.pose_landmarks, mpPose.POSE_CONNECTIONS)
- #如果我们想对33个关键点中的某一个进行特殊操作,需要先遍历33个关键点
- for id, lm in enumerate(results.pose_landmarks.landmark):
- #打印出来的关键点坐标都是百分比的形式,我们需要获取一下视频的宽和高
- h, w, c = img.shape
- print(id, lm)
- #将x乘视频的宽,y乘视频的高转换成坐标形式
- cx, cy = int(lm.x * w), int(lm.y * h)
- #使用cv2的circle函数将关键点特殊处理
- cv2.circle(img, (cx, cy), 5, (255, 0, 0), cv2.FILLED)
- #计算fps值
- cTime = time.time()
- fps = 1 / (cTime - pTime)
- pTime = cTime
- cv2.putText(img, str(int(fps)), (70, 50), cv2.FONT_HERSHEY_PLAIN, 3,
- (255, 0, 0), 3)
- cv2.imshow("Image", img)
- cv2.waitKey(1)

Results as shown below:



Because mediapipe is a bottom-up algorithm, it can be seen that even if the person does not fully appear, the key points can be identified, and then connected together, the effect is still very good for single-person gesture recognition.
Category of website: technical article > Blog
Author:Sweethess
link:http://www.pythonblackhole.com/blog/article/80198/a9c2e251051eb5bb6002/
source:python black hole net
Please indicate the source for any form of reprinting. If any infringement is discovered, it will be held legally responsible.
name:
Comment content: (supports up to 255 characters)
no articles