
Python对职业人群体检数据进行分析与可视化(附源码 超详细)
posted on 2023-06-06 11:12 read(658) comment(0) like(18) collect(2)
If you need source code and data sets, please like and follow the collection and leave a private message in the comment area~~~
Data Analysis of Professional Group Examination
Some occupational hazards will affect human blood and other systems. The following is an analysis of part of the data of a professional group examination
The implementation steps are as follows
1: import module
2: Get data
Import the pending data testdata.xls and display the first five rows

3: Analyze data
First look at the data type table structure and count the number of vacant values in each field



Next, delete the columns that are all empty and the data whose ID number is empty
remove all empty columns

DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
Function role: delete rows or columns with null values¶
axis: dimension, axis=0 means index row, axis=1 means columns column, the default is 0
how: "all" means that all the elements in this row or column are missing (nan) before deleting this row or column, "any" means that as long as there are missing elements in this row or column, this row or column will be deleted
thresh: delete only when there are at least thresh in a row or a column.
subset: Select columns with missing values in a subset of some columns to delete, and columns or rows with missing values that are not in the subset will not be deleted (there is an axis to determine whether it is a row or a column)
inplace: Whether the new data is saved as a copy or directly modified on the original data
Delete the data whose ID number is empty

Standardize the "Year of starting to work" as a 4-digit year, such as "2018", and modify the column name to "Working time
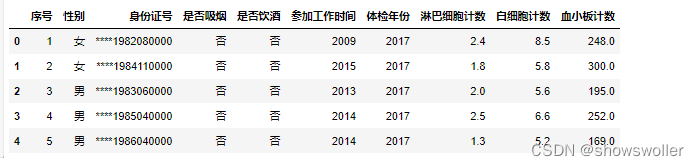
Add two columns of "working age" (year of physical examination - working time) and "age" (time of physical examination - year of birth)
See if there are missing values pending and delete all missing values
Then you can see that the missing values in one of the columns of working hours have been deleted, and you can also see that there are 38 missing values in the year of physical examination that have also been deleted.

The data types of ID number, working time, and year of physical examination are all objects, which need to be converted to int64 type. In addition, there are many abnormal data in the column of year of physical examination, and there are years after many years. For the year of physical examination Data for time extraction
Add the two columns of working years and age

Count the mean value of white blood cell counts of different genders and draw a histogram

Count the white blood cell counts of different age groups and draw a histogram. The age groups are divided into 4 groups: less than or equal to 30 years old, 31-40 years old, 41-50 years old and greater than 50 years old
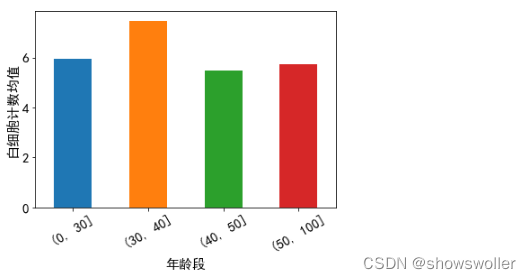
After the above series of work, it can be clearly seen that some distribution characteristics of the data are helpful for subsequent solutions
the code
Part of the code is as follows, all the codes are required, please like, follow, and leave a private message in the comment area~~~
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
- plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
- %matplotlib inline
- df = pd.read_excel("testdata.xls")#这个会直接默认读取到这个Excel的第一个表单
- data =df.head()#默认读取前5行的数据
- data
- df.info()
- df.dtypes
- df.shape
- df.isnull().sum()
-
- df.dropnaaxis=1, how='all',inplace= True)#将全部项都是nan的列删除
- df.head()
- df.dropna(how='any',subset=['身份证号'],inplace= True)
- df.isnul().sum()
- df1 = df
- df.shape
- df.开始从事某工作年份 = df.开始从事某工作年份.str[0:4]
- df.rename(columns={"开始从事某工作年份": "参加工作时间"},inplace=True)
- df.head()
-
- df.isnull().sum()
- df1 = df.dropna(subset=['参加工作时间'],how='any')
- df1.isnull().sum()
- df1.isnull().sum()
- df2 = df1.dropna(subset=['体检年份'],how='any')
- # ()
- df2.isnull().sum()
- #参加工作时间转换为int64类型
- #首将体检年份转换为str类型
- data['体检年份'] = data.体检年份.astype('str')
- #切片取前4位值之后再将体检年份转换为int64类型
- data.体检年份 = data.体检年份.str[0:4].astype("int64")
- #取身份证的第4位-第7位,并转换为int64类型
- data["出生年份"] = data.身份证号.str[4:8].astype('int64')
- d.head()
- data.参加工作时间 = data.参加工作时间.astype('int64')
- data['体检年份'] = data.体检年份.astype('str')
- data.体检年份 = data.体检年份.str[0:4].astype("int64")
- data["出生年份"] = data.身份证号.str[4:8].astype('int64')
- data.head()
- data = data.eval('工龄 = 体检年份-参加工作时间')
- data = data.eval("年龄= 体检年份- 出生年份")
- data.head()
-
- import matplotlib
- matplotlib.rcParams['font.size'] = 15
- matplotlib.rcParams['font.family'] = 'SimHei'
-
- # mean.plot(kind='bar') #series.plot(kind='bar')
- mean.plot.bar()
- plt.xticks(rotation=0)
- plt.ylabel("白细胞均值")
- data['年龄段'] = pd.cut(data.年龄, bins=[0,30,40,50, 100])
- count = data.groupby('年龄段')['白细胞计数'].mean()
- count
-
- count.plot(kind = "bar")
- plt.xticksotation=30)
- plt.ylabel("白细胞计数均值")

It's not easy to create and find it helpful, please like, follow and collect~~~
Category of website: technical article > Blog
Author:Fiee
link:http://www.pythonblackhole.com/blog/article/79916/dcd381fe71cac60143bd/
source:python black hole net
Please indicate the source for any form of reprinting. If any infringement is discovered, it will be held legally responsible.
name:
Comment content: (supports up to 255 characters)
no articles