
windows使用YOLOv8训练自己的模型(0基础保姆级教学)
posted on 2023-05-21 16:48 read(922) comment(0) like(3) collect(4)
Table of contents
1. Use labelimg to make a data set
1.2. Install the library and start labelimg
2. Use YOLOv8 to train the model
2.1, download library - ultralytics (remember to change the source)
1. Start train.py for training
2. We can directly use commands for training
1. Why is the labels.cache file generated during training?
4. Does yolov8 waste electricity during training?
4. Recommended videos and articles
foreword
python version>3.6 [mine is 3.9]
Pip source change: [to facilitate the installation of subsequent libraries]Record pip problems (solve the problem of slow download and upgrade failure)_pip upgrade is too slow_Pan_peter's Blog-CSDN BlogEvery time I make a mistake in the installation of a certain library, and then troubleshoot the problem, it is a waste of time! ! ! Record it here and take it as a warning! It is not recommended to use the library installation on pycharm, because there is no obvious error prompt, and it is impossible to judge the problem well. When there are multiple versions of python on the computer, remember to use pip -version to check which version is used!
https://blog.csdn.net/Pan_peter/article/details/129553679
1. Use labelimg to make a data set
1.1. Download labelimg
Download link:
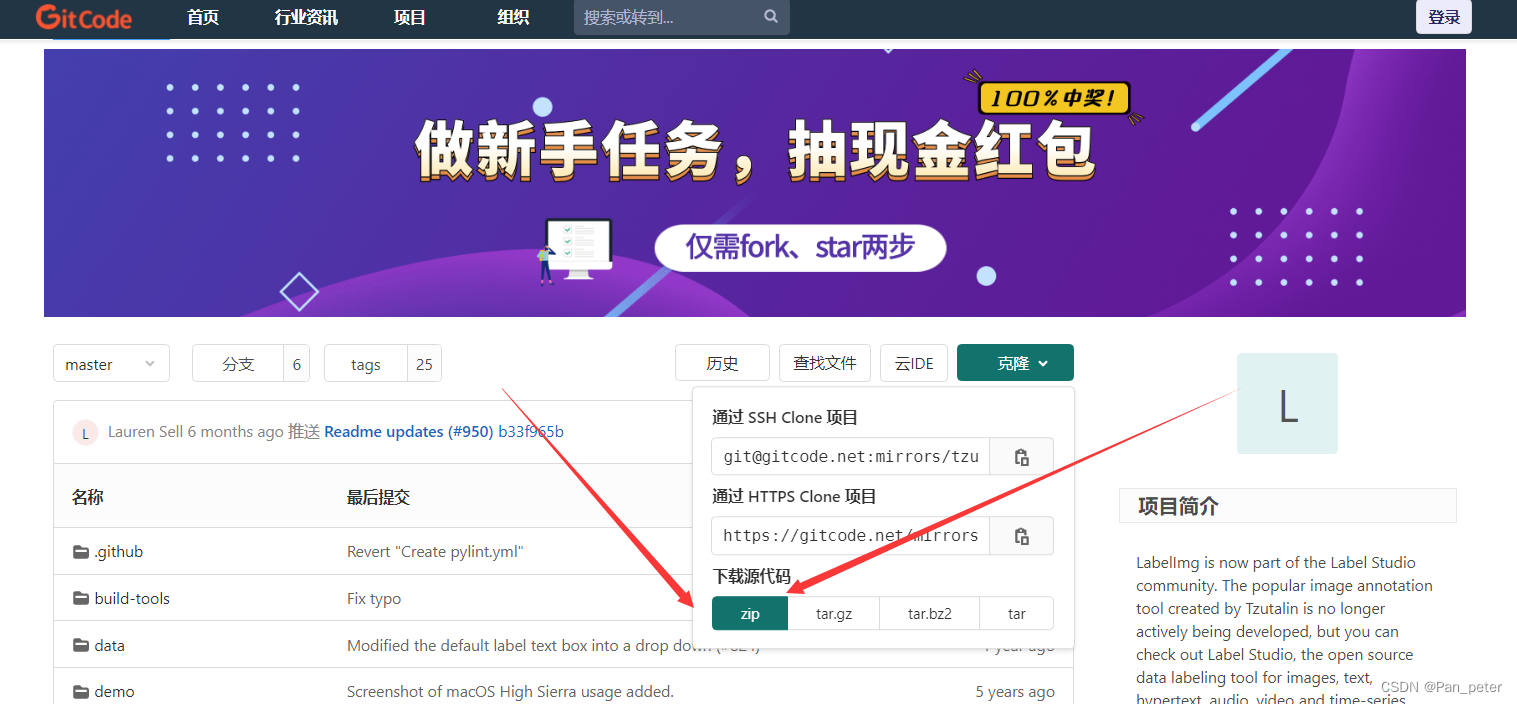
After downloading the compressed package, just unzip it! [It is best not to have Chinese in the decompression path! 】
My path: E:\labelimg
1.2. Install the library and start labelimg
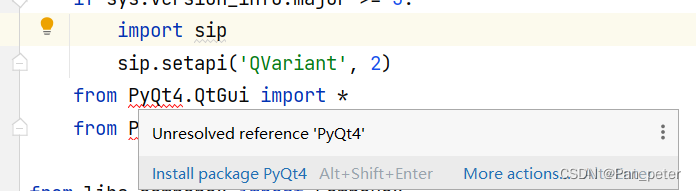
1. According to the required red lines, install them one by one!
If you don't know how to download with pycharm, open the console directly:
2. In [Command Prompt], start labelimg

"pyrcc5 -o libs/resources.py resources.qrc" is a command executed in the terminal (command line interface).
What it means is to compile a file named "resources.qrc" into Python code and save the output to a file named "libs/resources.py".
In this command:
- "pyrcc5" is a command-line tool for manipulating Qt resource files (.qrc),
- "-o libs/resources.py" specifies the location and name of the output file,
- "resources.qrc" is the name of the resource file to compile.
This command is usually used to compile Qt's resource files into Python code for use in Python applications, such as accessing through the PyQt or PySide modules.
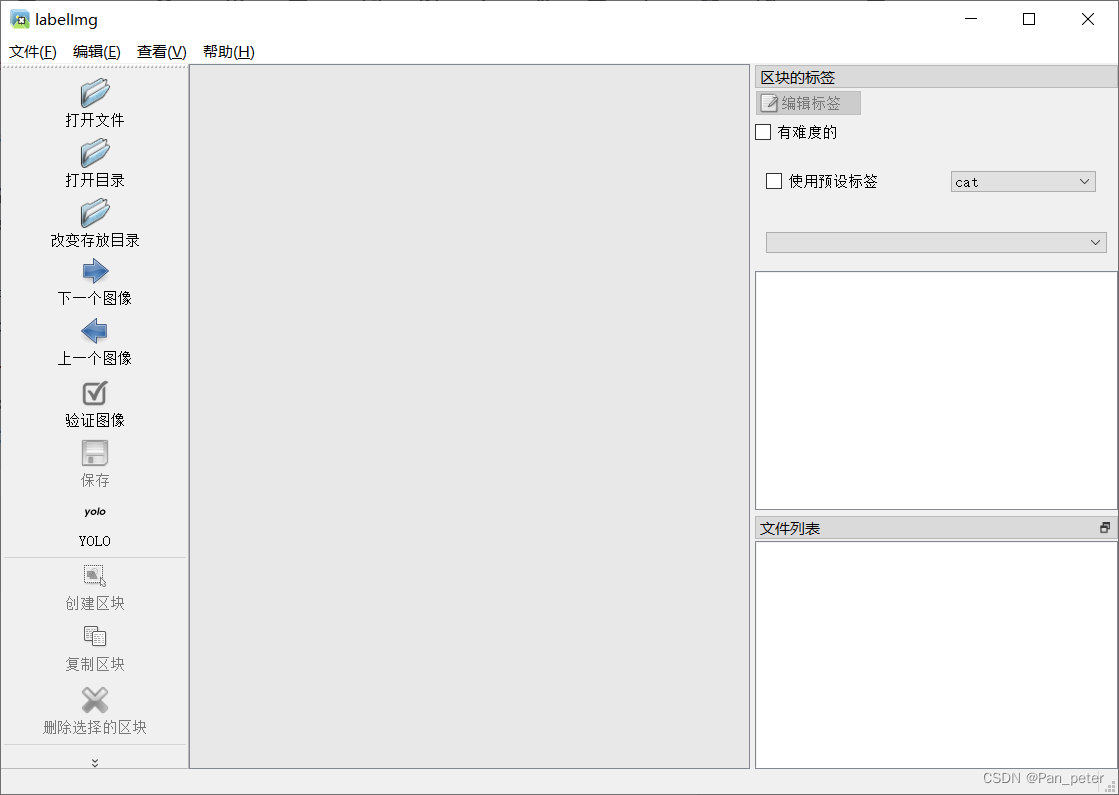
Started successfully:
1.4. Make YOLO dataset
1. Switch to YOLO format
2. Open the directory [our target photos exist in that directory]

3. Select the storage directory [used to save our calibrated data set]
4. Start calibration
- After pressing w, press the left button to drag
- Detailed operations can be skipped for learning
- There is also class (class) customization
Notice:
- Switch the keyboard input method to English, press the "W" key, and the crosshairs in the figure below will appear in the labelimg
- Press and hold the left mouse button to bring the target into the grid area. Note that the grid area should be as small as possible
- Can be set to save automatically
Quick operation: http://t.csdn.cn/ecW9v
Custom class: open data/predefined_classes.txt, you can modify the default class
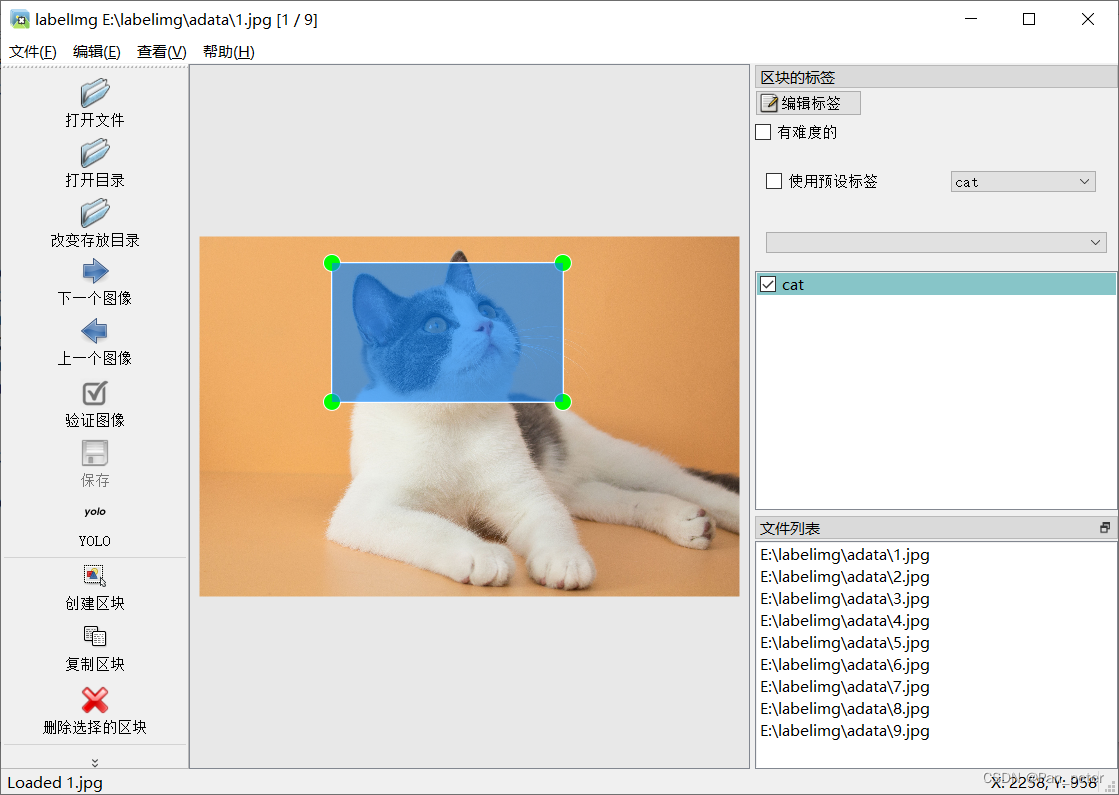

5. Check the dataset
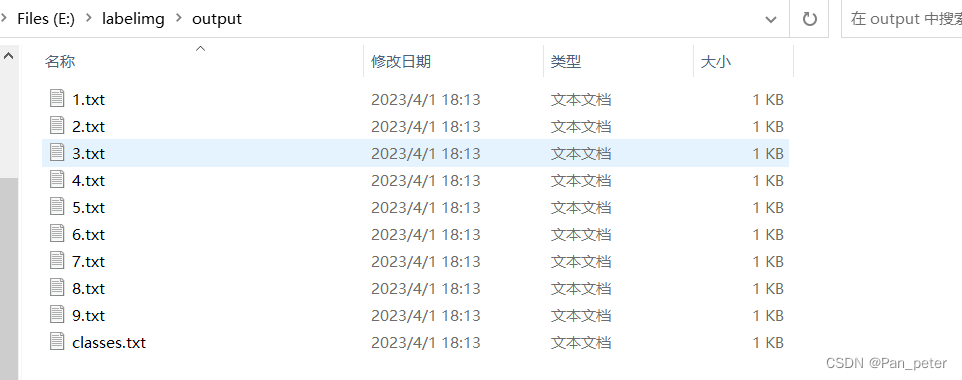
At this point, the dataset creation is complete!
2. Use YOLOv8 to train the model
2.1, download library - ultralytics (remember to change the source)
pip install ultralytics2.2. Data template download
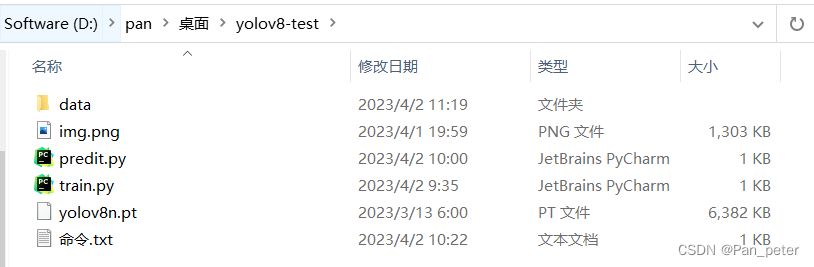
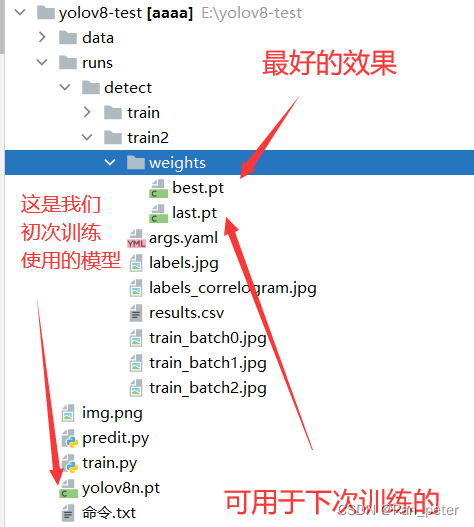
Directory Structure
- E:.
- │ img.png
- │ predit.py
- │ train.py
- │ yolov8n.pt
- │ 命令.txt
- │
- └─data
- │ cat.yaml
- │ yolov8n.yaml
- │
- ├─test
- │ ├─images
- │ │ 8.jpg
- │ │
- │ └─labels
- │ 8.txt
- │
- ├─train
- │ │ labels.cache
- │ │
- │ ├─images
- │ │ 1.jpg
- │ │ 2.jpg
- │ │ 3.jpg
- │ │ 4.jpg
- │ │ 5.jpg
- │ │ 6.jpg
- │ │ 7.jpg
- │ │
- │ └─labels
- │ 1.txt
- │ 2.txt
- │ 3.txt
- │ 4.txt
- │ 5.txt
- │ 6.txt
- │ 7.txt
- │
- └─val
- │ labels.cache
- │
- ├─images
- │ 9.jpg
- │
- └─labels
- 9.txt

The content of cat.yaml [It is best not to have Chinese in the path! ! ! 】
This is a YOLOv8 configuration file, which includes the following three configuration items:
train: E:/yolov8-test/data/train/images
Specify the path of the training dataset, which is set to E:/aaaa/data/train in this example.
images contains all training images,
and labels correspond to the annotation files.val: E:/yolov8-test/data/val/images
Specify the path of the validation data set, which is set to E:/aaaa/data/val in this example. The validation dataset is used to test the trained model and it is similar to the training dataset.
images contains all training images,
and labels correspond to the annotation files.test: E:/yolov8-test/data/test/images
Specify the path of the test data set, which is set to E:/aaaa/data/test in this example.
The test data set is the data set used to test the accuracy of the model after training.
images contains all training images,
and labels correspond to the annotation files.nc: 1
Specifies the number of categories in the dataset, in this case set to 1, which is one category (cat).
names: ['cat']
Specify the name of the category, in this example there is only one category named cat.
In short:
The image files of the dataset are stored in the images directory.
Label files are stored in the labels directory.
Generally, it is stored according to the ratio of 7:2:1, for example:
You have 100 pictures and 100 labels, then
- There are 70 pictures and 70 labels in the train
- There are 20 pictures and 20 labels in val
- There are 10 pictures and 10 labels in the test
2.3. Start training
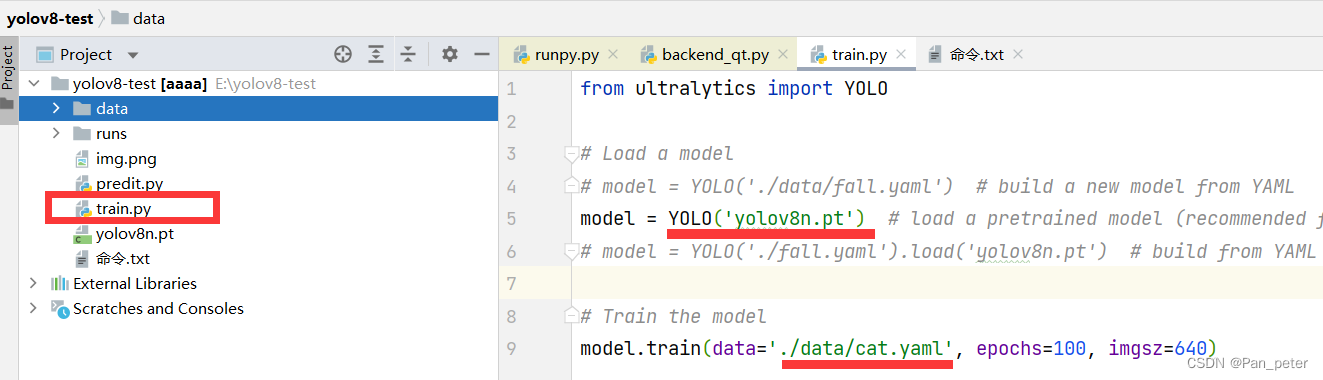
1. Start train.py for training
Open train.py, select cat.yaml configuration file and yolov8n.pt model to start training
2. We can directly use commands for training

3. Other issues
1. Why is the labels.cache file generated during training?
In YOLOv8, a file named "labels.cache" is generated by default, which records the image label information in the training data set, including image file path and label information.
The purpose of this file is to speed up data reading and loading during model training, thereby increasing the training speed.
During the model training process, the image files and label information in the training data set need to be loaded into the memory for training. For large-scale data sets, this process may be very time-consuming and affect the training efficiency. In order to avoid this problem, YOLOv8 pre-reads and caches the image files and label information into the memory by generating the "labels.cache" file. During the training process, the data can be read directly from the cache, reducing the IO during training. operation, thus greatly shortening the training time.
此外,缓存的图像数据和标签信息属于原始训练数据集,不会改变图片的数据和标签信息,这意味着可以在缓存文件中进行快速的训练,而无需频繁地重新读取原始数据集。这种方法可以有效地缩短模型训练的时间,并提高训练效率和精度。
2、YOLOv8的训练图像和相应的标注文件应该放同一个文件夹里吗?还是应该分开放?
YOLOv8的训练需要使用图像文件和相应的标注文件,通常来讲,这些文件的命名对应方式需要相同:
例如图像文件名为"image001.jpg",那么相应的标注文件应该命名为"image001.txt"。
至于这些文件应该分别放在哪里,是一种较为灵活的安排。通常情况下,它们可以放在同一个文件夹里,以便于管理和处理。这样可以方便地查找图片和对应的标注文件,而且文件夹的名称可以根据具体任务、类别和编号等方式进行命名,便于进行管理和实验效果的观察。
当然,您也可以将图像文件和相应的标注文件分别放在不同的文件夹中,而文件夹的名称可以根据具体任务要求进行命名,例如划分成训练集(training set)和测试集(test set)。一般来讲,这样的做法对于数据管理和处理来说比较繁琐,但对于某些特定任务的处理可能会有帮助。
综上所述,将图像文件和相应的标注文件放在同一个文件夹中是比较常见的做法,但也需要根据实际情况进行具体的安排。
3、yolov8训练自己的模型,大概需要多少图片作为训练集?效果合适?又需要训练多少轮呢?
YoloV8的训练数量并没有一个固定的标准,通常的做法是根据自己的数据量和特定任务的困难程度来设计数据集大小。
一般来说,训练集的大小应该足够覆盖任务中的各种不同场景和对象,以确保模型具备较好的鲁棒性。为了取得较好的训练效果,建议训练集至少要有1000张图片,最好有数万张图片。
同时,训练集中每个类别的数量也需要足够。如果某个类别的样本数量太少,可能导致模型无法很好地学习该类别的特征,从而导致训练不充分而无法取得理想的效果。因此,建议每个类别至少有几百张训练图片。
对于训练次数,一般可以通过观察模型在验证集上的表现来确定。如果模型在验证集上的表现不断提升,那么可以逐渐增加训练轮数,直到模型在验证集上的表现达到一个 稳定的状态。
通常,训练轮数越多,模型的性能会越好,但是过多的训练轮数可能导致过拟合,所以需要在充分训练的同时避免过度拟合。常见的训练轮数通常在50-200轮之间。
4、yolov8训练时会十分浪费电吗
YoloV8是一种非常先进的目标检测算法,因其检测速度快、精度高而被广泛应用于计算机视觉领域。
在训练阶段,YoloV8需要使用大量的计算资源,包括CPU、GPU、Memory等。由于训练需要运算量比较大,因此在计算资源不足的情况下,使用YoloV8训练会十分浪费电。
如果你要使用YoloV8进行训练,建议使用高性能显卡(例如NVIDIA RTX 3090等),这样可以大大减少训练时间,也能降低电能消耗。同时,使用最新的深度学习框架(例如PyTorch、TensorFlow等)也能提升训练效率和准确性,从而避免出现浪费电的情况。
另外,还可以使用电力管理软件来监控计算机的电量消耗并进行一些优化设置,例如关闭不必要的应用程序、降低屏幕亮度等。这样不仅可以节省电力,还可以 prolong电池寿命。
5、在yolov8中,yaml中的文件只指向了图片位置,但程序仍然可以找到同级文件夹中的label标定数据,这是为什么?
在 YOLOv8 中,当你通过指定 YAML 配置文件来指定图像文件的位置时,实际上在执行 YOLOv8 程序时,程序会默认去同级目录下找到与该图像文件同名的 .txt 标注文件。
这是因为 YOLO 系列算法中目标检测任务需要同时标定图像中检测目标的位置、类别和置信度等信息,所以除图像外,还需要提供对应的标注信息。在 YOLOv8 中,.txt 标注文件与对应图像文件同名,其格式也是固定的,每一行表示一个标注框的信息,其中包括车辆类别、中心点坐标、边界框宽高、以及置信度等信息。
因此,无论你通过配置文件指定哪个图像文件,程序在执行时都会去同级目录寻找相同文件名的 .txt 文件作为该图像的标注信息。这种设计简化了数据集的管理和使用,并且减少了用户在制作数据集时的操作繁琐程度。
6、为什么要将.pt模型导出为onnx?
1、平台无关性:ONNX是一种跨平台的深度学习模型交换格式,可以在不同的深度学习框架和硬件平台之间进行方便的转换和部署,提高部署的灵活性。
2、快速预测:ONNX格式的模型具有非常快的推理速度和较低的内存占用,这意味着在运行推理任务时可以更快地完成,可以提高推理速度和性能,并减少计算资源的使用。
3、生态环境:ONNX格式受到了众多深度学习框架以及众多硬件加速平台的支持,可以使用多种语言和平台进行部署,使得训练后的模型可以被更广泛的应用所使用。
因此,将YOLOv8训练得到的模型导出为ONNX格式,有助于更好地部署模型,并在不同的框架和平台之间进行快速交换和移植,提高模型的效用和可用性。
7、如何快速入门 YOLOv5 :
- 准备输入数据:YOLOv5 需要训练数据,以便在其上进行训练。你需要一个包含图像及其注释的数据集。YOLOv5 接受 COCO 格式或自定义格式的注释。你可以通过在 ImageNet 或 COCO 数据集上进行预训练来加快训练速度。
- 安装 YOLOv5:YOLOv5 可以通过 Clone GitHub 存储库或使用 pip 安装在本地计算机上。
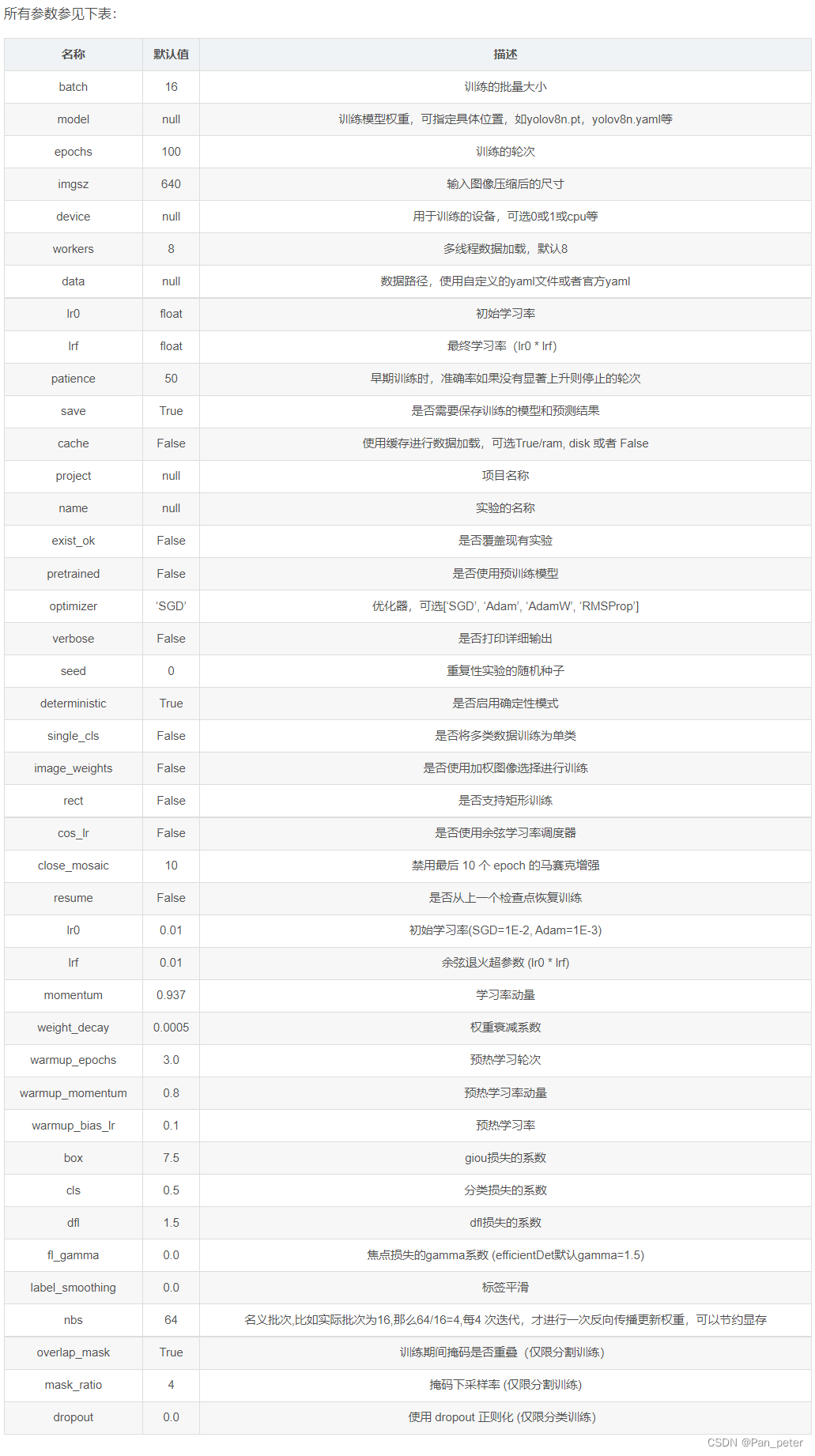
- 配置超参数:通过更改 YAML 配置文件中的超参数,对 YOLOv5 进行各种设置,例如网络架构、训练和预测设置以及优化器参数等。
- 训练模型:运行
train.py脚本开始训练模型。你可以通过设置训练时间来控制模型在数据集上的训练次数。- 转换模型: 在训练完成后使用
export.py脚本将模型转换为 ONNX、TensorFlow Lite、TorchScript 等格式,以便在设备上部署模型。- 运行模型:在部署后,你可以使用
detect.py脚本来运行模型。除了以上步骤外,你还需要了解 YOLOv5 的原始论文和代码、深度学习基础知识、Python 编程等。确定你已具备这些基础知识后,可以通过逐步完成上述步骤来快速入门 YOLOv5。
四、推荐视频与文章
1、视频
 https://www.bilibili.com/video/BV1js4y1Y77w
https://www.bilibili.com/video/BV1js4y1Y77w2、文章
Category of website: technical article > Blog
Author:Abstract
link:http://www.pythonblackhole.com/blog/article/25308/053455b5ad2cb063da59/
source:python black hole net
Please indicate the source for any form of reprinting. If any infringement is discovered, it will be held legally responsible.
name:
Comment content: (supports up to 255 characters)
no articles