
Python crawls website data (including code and explanation)
posted on 2023-05-21 16:29 read(755) comment(0) like(9) collect(3)
Tip: This crawling is carried out using xpath , and it is OK to follow the order of the articles;
Article directory
1. Preparation for data collection
2. Set the crawling location and path (xpath)
1. Create a dataframe to store data
3. Export the data into a csv table
foreword
The website crawled this time is the Fangtianxia website;
It contains a lot of real estate information: https://newhouse.fang.com/house/s/b81-b91/
I did a step-by-step screening on the website, that is, to select the listings in Beijing and its surrounding areas. If you want to crawl the listing information in other cities, it is also very simple, just change the url information.
1. Preparation for data collection
1. Observe the url rule
It is observed that there are many webpages for housing listings in Beijing and surrounding areas, and the pattern of URLs can be found by turning a few pages:
The URL is: https://newhouse.fang.com/house/s/ + b81-b9 X + /; where X is the page number

Use for loop to traverse all pages:
- for i in range(33): # 每页20个小区,共648个小区
- url = 'https://newhouse.fang.com/house/s/b81-b9' + str(i+1) + '/'
pip install fake_useragent library:
fake-useragent can pretend to generate the User Agent value in the headers request header, and disguise the crawler as the normal operation of the browser.
!pip install fake_useragentImport the packages that will be used next:
- ## 导包
- from lxml import etree
- import requests
- from fake_useragent import UserAgent
- import pandas as pd
- import random
- import time
- import csv
Set request parameters: You need to replace the two values of 'cookie' and 'referer':
'cookie': Every time you visit the website server, the server will set a cookie locally to indicate the identity of the visitor. Remember to manually fill in a cookie according to the fixed method every time you use it.
'referer': request parameter, identifying which page the request came from.
- # 设置请求头参数:User-Agent, cookie, referer
- headers = {
- 'User-Agent' : UserAgent().random,
- 'cookie' : "global_cookie=kxyzkfz09n3hnn14le9z39b9g3ol3wgikwn; city=www; city.sig=OGYSb1kOr8YVFH0wBEXukpoi1DeOqwvdseB7aTrJ-zE; __utmz=147393320.1664372701.10.4.utmcsr=mp.csdn.net|utmccn=(referral)|utmcmd=referral|utmcct=/mp_blog/creation/editor; csrfToken=KUlWFFT_pcJiH1yo3qPmzIc_; g_sourcepage=xf_lp^lb_pc'; __utmc=147393320; unique_cookie=U_bystp5cfehunxkbjybklkryt62fl8mfox4z*3; __utma=147393320.97036532.1606372168.1664431058.1664433514.14; __utmt_t0=1; __utmt_t1=1; __utmt_t2=1; __utmt_t3=1; __utmt_t4=1; __utmb=147393320.5.10.1664433514",
- # 设置从何处跳转过来
- 'referer': 'https://newhouse.fang.com/house/s/b81-b91/'
- }
Please refer to the link for the specific modification method:
[Tencent document] How to change 'cookie' and 'referer':
https://docs.qq.com/doc/DR2RzUkJTQXJ5ZGt6
I can only follow the link, and I have been reviewing but 555~
2. Set the crawling location and path (xpath)
Because crawling data mainly relies on 'determining the location of the target data', you must first figure out the location of the target data (which part of the div is located);
First send the request:
- url = 'https://newhouse.fang.com/house/s/b81-b91/'# 首页网址URL
- page_text = requests.get(url=url, headers=headers).text# 请求发送
- tree = etree.HTML(page_text)#数据解析
The data I want to crawl is mainly: real estate name, number of comments, house area, detailed address, area, and average price .
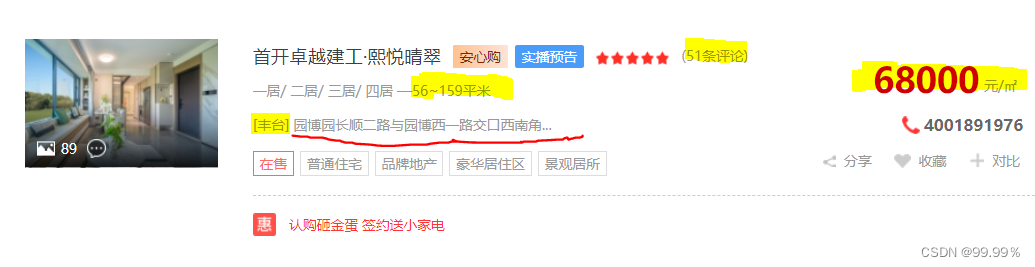
The code has been pasted below, and the specific method description is still a link:
[Tencent Documents] Explanation on obtaining specific crawling locations
https://docs.qq.com/doc/DR3BFRW1lVGFRU0Na
- # 小区名称
- name = [i.strip() for i in tree.xpath("//div[@class='nlcd_name']/a/text()")]
- print(name)
- print(len(name))
-
- # 评论数
- commentCounts = tree.xpath("//span[@class='value_num']/text()")
- print(commentCounts)
- print(len(commentCounts))
-
- # 房屋面积
- buildingarea = [i.strip() for i in tree.xpath("//div[@class='house_type clearfix']/text()")]
- print(buildingarea)
- print(len(buildingarea))
-
- # 详细地址
- detailAddress = tree.xpath("//div[@class='address']/a/@title")
- print(detailAddress)
- print(len(detailAddress))
-
- # 所在区
- district = [i.strip() for i in tree.xpath("//div[@class='address']//span[@class='sngrey']/text()")]
- print(district)
- print(len(district))
-
- # 均价
- num = tree.xpath("//div[@class='nlc_details']/div[@class='nhouse_price']/span/text() | //div[@class='nlc_details']/div[@class='nhouse_price']/i/text()")
- unit = tree.xpath("//div[@class='nlc_details']/div[@class='nhouse_price']/em/text()")
- price = [i+j for i,j in zip(num, unit)]
- print(price)
- print(len(price))

The data collected at this time also contains symbols or units such as [] square brackets, — horizontal bar, "square meter", so simple split processing should be performed on the data to extract the really needed data:
- # 评论数处理
- commentCounts = [int(i.split('(')[1].split('条')[0]) for i in commentCounts]
- print(commentCounts)
-
- # 详细地址处理
- detailAddress = [i.split(']')[1] for i in detailAddress]
- print(detailAddress)
-
- # 所在区字段处理
- district = [i.split('[')[1].split(']')[0] for i in district]
- print(district)
-
- # 房屋面积处理
- t = []
- for i in buildingarea:
- if i != '/' and i != '':
- t.append(i.split('—')[1].split('平米')[0])
- print(t)
- print(len(t))
2. Data collection
1. Create a dataframe to store data
- df = pd.DataFrame(columns = ['小区名称', '详细地址', '所在区', '均价', '评论数'])
- df
2. Start crawling
For the convenience of this map, only the first 10 pages are crawled, because the listings in the back often have little information, either without area information or without the area where they are located.
- for k in range(10):
- url = 'https://newhouse.fang.com/house/s/b81-b9' + str(k+1) + '/'
- page_text = requests.get(url=url, headers=headers).text #请求发送
- tree = etree.HTML(page_text) #数据解析
-
- # 小区名称
- name = [i.strip() for i in tree.xpath("//div[@class='nlcd_name']/a/text()")]
- # 评论数
- commentCounts = tree.xpath("//span[@class='value_num']/text()")
- # 详细地址
- detailAddress = tree.xpath("//div[@class='address']/a/@title")
- # 所在区
- district = [i.strip() for i in tree.xpath("//div[@class='address']//text()")]
- # 均价
- num = tree.xpath("//div[@class='nlc_details']/div[@class='nhouse_price']/span/text() | //div[@class='nlc_details']/div[@class='nhouse_price']/i/text()")
- unit = tree.xpath("//div[@class='nlc_details']/div[@class='nhouse_price']/em/text()")
- price = [i+j for i,j in zip(num, unit)]
-
- #评论数处理
- commentCounts = [int(i.split('(')[1].split('条')[0]) for i in commentCounts]
- #详细地址处理
- tmp1 = []
- for i in detailAddress:
- if ']' in i:
- tmp1.append(i.split(']')[1])
- continue
- tmp1.append(i)
- detailAddress = tmp1
- #所在区处理
- tmp2 = []
- for i in district:
- if ']' in i and '[' in i:
- tmp2.append(i.split(']')[0].split('[')[1])
- district = tmp2
-
-
- dic = {'小区名称':name, '详细地址':detailAddress, '所在区':district, '均价':price, '评论数':commentCounts}
- df2 = pd.DataFrame(dic)
- df = pd.concat([df,df2], axis=0)
- print('第{}页爬取成功, 共{}条数据'.format(k+1, len(df2)))
-
- print('全部数据爬取成功')
3. Export the data into a csv table
df.to_csv('北京小区数据信息.csv',index=None)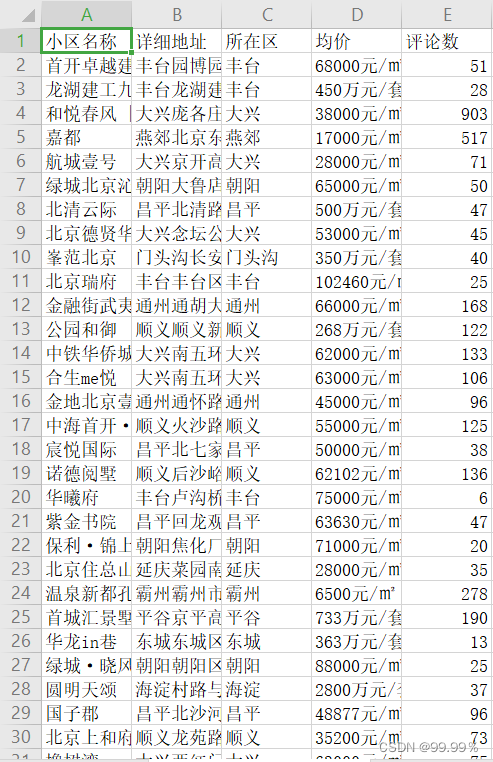
Summarize
To be honest, the crawling method used in this article is simple and the information is correct, but there are some deficiencies. For example, when some real estate information is vacant, it cannot be collected according to null, but an error will be reported, so my existing solution is in Manually set conditions in the loop to skip vacant information.
I will continue to optimize this method~
Category of website: technical article > Blog
Author:Disheartened
link:http://www.pythonblackhole.com/blog/article/25282/e821404585b4c30c0945/
source:python black hole net
Please indicate the source for any form of reprinting. If any infringement is discovered, it will be held legally responsible.
name:
Comment content: (supports up to 255 characters)
no articles