
【第十一届泰迪杯数据挖掘挑战赛】A 题:新冠疫情防控数据的分析 思路+代码(持续更新)
posted on 2023-05-21 17:28 read(928) comment(0) like(13) collect(2)
[The 11th Teddy Cup Data Mining Challenge] Question A: Analysis ideas + codes for COVID-19 epidemic prevention and control data (continuously updated)
problem background
自 2019 年底至今,全国各地陆续出现不同程度的新冠病毒感染疫情,如何控制疫情蔓
延、维持社会生活及经济秩序的正常运行是疫情防控的重要课题。大数据分析为疫情的精准
防控提供了高效处置、方便快捷的工具,特别是在人员的分类管理、传播途径追踪、疫情研
判等工作中起到了重要作用,为卫生防疫部门的管理决策提供了可靠依据。疫情数据主要包
括人员信息、场所信息、个人自查上报信息、场所码扫码信息、核酸采样检测信息、疫苗接
种信息等。
本赛题提供了某市新冠疫情防疫系统的相关数据信息,请根据这些数据信息进行综合分
析,主要任务包括数据仓库设计、疫情传播途径追踪、传播指数估计及疫情趋势研判等。
Solve the problem
- According to the travel time and place of the positive person in the nucleic acid test, the close contacts are tracked, and the result is saved in the
"result1.csv" file (see the result1.csv in Attachment 1 for the file template). - Based on the results of Question 1, track the corresponding secondary contacts according to their travel time and location, and save the results
in the "result2.csv" file (see result2.csv in Appendix 1 for the file template). - Build a model to analyze the impact of vaccination on the virus transmission index.
- According to the number of positive people and the scope of radiation, analyze and determine the places that need key control.
- In order to carry out epidemic prevention and control and personnel management more accurately, what relevant data do you think need to be collected? Build a model based on these
data to analyze the effect of precise prevention and control.
Note When solving the above problems, it is required to establish a data warehouse in combination with the data information table provided by the competition to realize the
content of data governance. Please clearly explain in the paper what data governance work has been done and how to achieve it.
! ! Note: The following code is written on Aistudio, so there is no relevant database established. According to the title, you are required to create a database yourself, and then read it in the code.
code download
Code download address: The 11th Teddy Cup Data Mining Challenge-ABC-Baseline
-
Everyone Fork the project to view all the codes (free)
-
This project is for learning reference only, encourage everyone to promote learning through the competition, in order to ensure the fairness of the competition (only primary Baseline and simple idea sharing are provided)
-
If suspected of violating the rules, the project will be deleted as soon as possible
注:思路仅代表作者个人见解,不一定正确。
data analysis
- Import commonly used packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
- When importing the file, we found that there is a problem with the encoding of the attachment, so we need to encapsulate a function to obtain the encoding of the file
# 获取文件编码
import chardet
def detect_encoding(file_path):
with open(file_path,'rb') as f:
data = f.read()
result = chardet.detect(data)
return result['encoding']
- read all attachments
# 读取人员信息表
df_people = pd.read_csv('../datasets/附件2.csv',encoding = detect_encoding('../datasets/附件2.csv'))
# 读取场所信息表
df_place = pd.read_csv('../datasets/附件3.csv',encoding = detect_encoding('../datasets/附件3.csv'))
# 个人自查上报信息表
df_self_check = pd.read_csv('../datasets/附件4.csv',encoding = detect_encoding('../datasets/附件4.csv'))
# 场所码扫码信息表
df_scan = pd.read_csv('../datasets/附件5.csv',encoding = detect_encoding('../datasets/附件5.csv'))
# 核算采样检测信息表
df_nucleic_acid = pd.read_csv('../datasets/附件6.csv',encoding = detect_encoding('../datasets/附件6.csv'))
# 提交示例1
result = pd.read_csv('../datasets/result1.csv',encoding = detect_encoding('../datasets/result1.csv'))
# 提交示例2
result1 = pd.read_csv('../datasets/result2.csv',encoding = detect_encoding('../datasets/result2.csv'))
- Just look at the submission example
# 查看提交示例
result.head()
result1.head()
- As can be seen from the submission example, the question should be let us develop a strategy to track close contacts
- And obtain other information of close contacts according to the established strategy
- Descriptive statistics for each attachment
- In order to make descriptive statistics more intuitive, here is a function encapsulated for descriptive statistics
# 数据描述性统计
def summary_stats_table(data):
'''
a function to summerize all types of data
分类型按列的数据分布与异常值统计
'''
# count of nulls
# 空值数量
missing_counts = pd.DataFrame(data.isnull().sum())
missing_counts.columns = ['count_null']
# numeric column stats
# 数值列数据分布统计
num_stats = data.select_dtypes(include=['int64','float64']).describe().loc[['count','min','max','25%','50%','75%']].transpose()
num_stats['dtype'] = data.select_dtypes(include=['int64','float64']).dtypes.tolist()
# non-numeric value stats
# 非数值列数据分布统计
non_num_stats = data.select_dtypes(exclude=['int64','float64']).describe().transpose()
non_num_stats['dtype'] = data.select_dtypes(exclude=['int64','float64']).dtypes.tolist()
non_num_stats = non_num_stats.rename(columns={"first": "min", "last": "max"})
# merge all
# 聚合结果
stats_merge = pd.concat([num_stats, non_num_stats], axis=0, join='outer', ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, copy=True, sort=False).fillna("").sort_values('dtype')
column_order = ['dtype', 'count', 'count_null','unique','min','max','25%','50%','75%','top','freq']
summary_stats = pd.merge(stats_merge, missing_counts, left_index=True, right_index=True, sort=False)[column_order]
return(summary_stats)

- Personnel information table
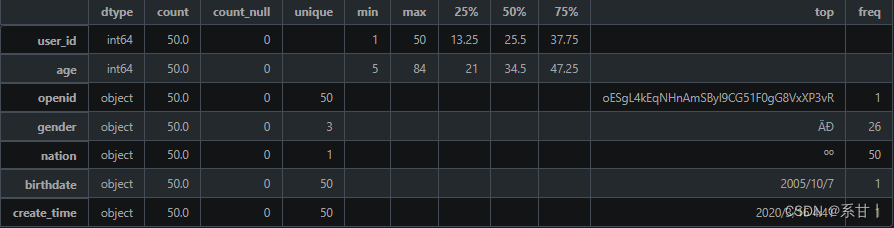
data description - user_id: Person ID, used to uniquely identify a person.
- openid: WeChat OpenID, used to associate the person's WeChat account information.
- gender: the gender of the person, the optional value is "male" or "female".
- nation: The ethnicity to which the person belongs, such as Han, Mongolian, and Tibetan.
- age: The age of the person, expressed as an integer.
- birthdate: The date of birth of the person, generally in the format "YYYY-MM-DD".
- create_time: The creation time of the record, which is used to record the update time of personnel information.
The analysis results below are based on sample data
-
A total of 50 pieces of data for people.
-
The age range is [5, 84]
Tips: The age span is relatively large. Naturally, we can do feature engineering based on age.
-
In gender, there are a total of three categories (there may be "unknown" categories), and only two categories are given in the title.
Tips: If you need to analyze or feature engineering based on gender later, you need to consider how to deal with the third category.
-
The nation has only one category, and there is a high probability that there will not be only one category in the full amount of data
Tips: If you need to use this column for aggregation analysis or feature engineering later, you can write dynamic code in Baseline .
-
Both birthdate and create_time correspond to 50 different times here
Tips: Pay attention to the beginning and end of the time, and compare it with other associated time, so that you can dig out more information or filter out some abnormal situations.
在全量数据中,时间大概率是有重复值的,也要考虑重复时间是否对解题有一定的影响亦或者重复时间的含义。 -
Data description of site information table
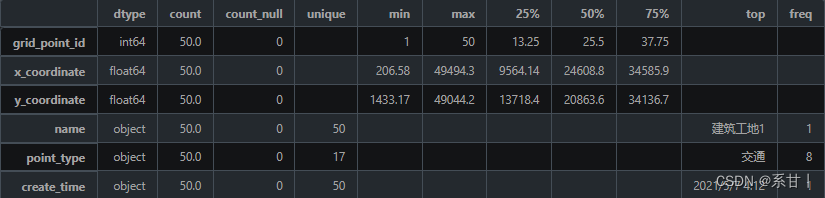
-
grid_point_id: site ID, used to uniquely identify a site.
-
name: The name of the place, such as a company, restaurant, supermarket, etc.
-
point_type: the type of place, such as business, entertainment, culture, medical care, etc.
-
x_coordinate: The X coordinate of the place, in meters, used to represent the location of the place on the map.
-
y_coordinate: Y coordinate of the place, in meters, used to represent the location of the place on the map.
-
create_time: The creation time of the record, which is used to record the update time of the location information.
The analysis results below are based on sample data
-
X, Y coordinates, which may be a good data to visualize
Tips: Other features can be visualized according to X and Y coordinates (including but not limited to name, point_type)
但是需要注意的是这只是示例数据,全量数据可能会比较庞大,可视化出来的效果可能没有理想那么好 -
name is the name of the venue, there is no duplicate data in the sample data (but it does not mean that there will be no duplicate data in the full amount of data)
Tips: For repeated place names, can they be aggregated for data statistics? or other
-
point_type place type, there are a total of 17 different place types in the sample data, among which the place type is entertainment is the most
Tips: Entertainment is only the result of sample data, not necessarily full data. More data analysis and perhaps feature engineering can be done based on this list of features
全量数据中有可能出现不同样本中X,Y值相同而对应的name或point_type等其它特征不同的情况。具体问题具体分析,不要什么都当作异常值 -
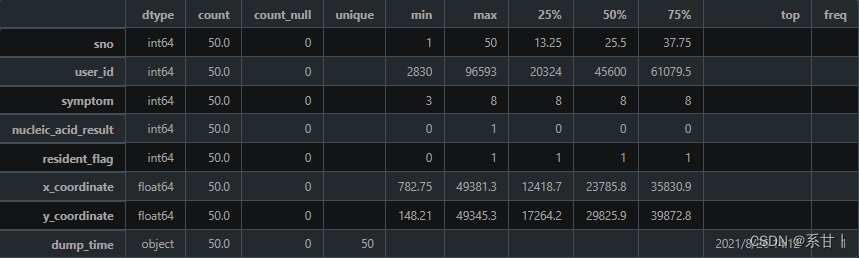
Data Description of Personal Self-examination and Reporting Information Form
-
sno: serial number, used to uniquely identify a self-inspection record.
-
user_id: Personnel ID, corresponding to the user_id in the "Personnel Information Table", used to associate self-examination records with corresponding personnel.
-
x_coordinate: The X coordinate of the reported location, in meters, used to indicate the location of the reported location on the map.
-
y_coordinate: The Y coordinate of the reported location, in meters, used to indicate the location of the reported location on the map.
-
symptom: Symptoms, used to record the symptoms of self-examiners. The optional values are: 1 Fever, 2 Fatigue, 3 Dry cough, 4 Nasal congestion, 5 Runny nose, 6 Diarrhea, 7 Dyspnea, 8 Asymptomatic.
-
nucleic acid_result: Nucleic acid test result, used to record the nucleic acid test status of the self-examiner. Possible values are: 0 Negative, 1 Positive, 2 Unknown (optional).
-
resident_flag: Whether it is a permanent resident, used to record the living conditions of the self-examiner. Possible values are: 0 unknown, 1 yes, 2 no.
-
dump_time: Reporting time, used to record the reporting time of self-inspection records.
The analysis results below are based on sample data
-
Symptom, it can be seen that the symptom category is incomplete in the sample data, and almost all of them are asymptomatic in the sample data (8)
Tips: In the full amount of data, all types of data should exist, so when writing the Baseline, you can consider writing the data analysis and visualization code first.
这一列特征还有一个特点是,在特征工程的时候,可以很好的和其它特征衍生出很多可解释性的交叉特征(eg:symptom-nucleic_acid_result) -
Nucleic_acid_result, resident_flag are the same
-
The X and Y coordinates here are different from those in the above table, you can dig out the difference between the two
Tips: According to the X and Y coordinates, it can be determined where the person reported the information.
-
dump_time (reporting time), you can combine this column with nuclear_acid_result, X, Y coordinates, you can dig out the occasions and people around the positive patients during the reporting period
-
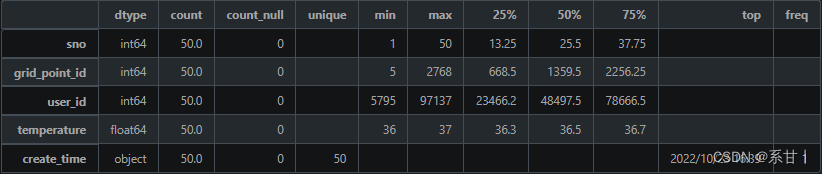
Data Description of Site Code Scanning Information Table
-
sno: serial number, used to uniquely identify a scan code record.
-
grid_point_id: location ID, corresponding to the grid_point_id in the "location information table", used to associate the scanning record with the corresponding location.
-
user_id: Personnel ID, corresponding to the user_id in the "personnel information table", used to associate the scan code record with the corresponding person.
-
temperature: Body temperature, used to record the body temperature of the code reader.
-
create_time: Scan code record time, used to record the time stamp of the scan code record.
The analysis results below are based on sample data
-
temperature (body temperature), in the example data, the minimum value is 36, and the maximum value is 37. These values seem to be in the range of normal human body temperature
Tips: You can cross-analyze this column with the characteristics in the personal information table. There is a high probability that there will be a body temperature of about 39 or higher in the full amount of data, so it is best to take this into consideration when writing the Baseline.
-
create_time (code scanning record time), we can take the time recorded by scanning the code as the person’s real-time body temperature time, and then compare it with the characteristics and time of other tables
Tips: For example, it can be compared with the reporting time and sampling date of the personal self-inspection reporting information form
-
Nucleic acid sampling and testing information table
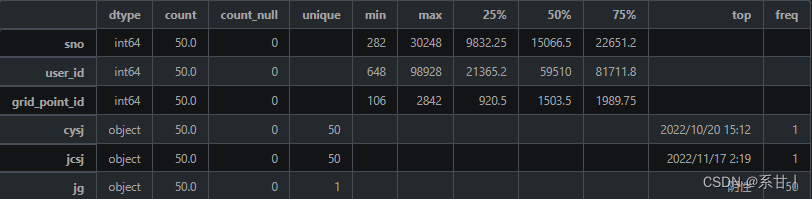
data description -
sno: serial number, used to uniquely identify a nucleic acid sampling record.
-
user_id: Personnel ID, corresponding to the user_id in the "Personnel Information Table", used to associate nucleic acid sampling records with corresponding personnel.
-
cysj: sampling date and time, used to record the date and time of nucleic acid sampling.
-
jcsj: detection date and time, used to record the date and time of nucleic acid detection.
-
jg: test result, used to record the result of nucleic acid test. Possible values are: Negative, Positive, Unknown.
-
grid_point_id: site ID, corresponding to the grid_point_id in the "site information table", used to associate nucleic acid sampling records with the corresponding site.
The analysis results below are based on sample data
-
There are two times here, one is the sampling time and the other is the detection time, so logically speaking, the detection time will be later than the sampling time
Tips: Be careful sailing for ten thousand years, we add a judgment here, if the judgment is true, then the sample can be regarded as an outlier
-
For the result column, the results are all negative in the example
Tips: We know that it will have three categories in total, so try to take it into account when writing Baseline
-
Since the first two questions did not involve Annex 7, there is no import here
-
Data visualization suggests that
the following visualizations can be done during data analysisSingle table visualization
-
Personnel information table: Demographic analysis can be performed, such as the distribution of gender, age, ethnicity, etc. It can also be associated with other tables through personnel ID.
-
Site information table: geographic information analysis can be performed, such as site distribution, site type distribution, site density, etc.
-
Personal self-examination and reporting information form: It can conduct epidemic monitoring and analysis, such as analysis of symptom distribution, correlation analysis between symptoms and nucleic acid test results, and location distribution of reporting personnel.
-
Site code scanning information table: It can carry out epidemic monitoring and analysis, such as the distribution of scanning code records, correlation analysis between scanning code records and nucleic acid test results, etc.
-
Nucleic acid sampling and testing information form: It can carry out epidemic monitoring and analysis, such as the distribution of positive people, analysis of positive rate of nucleic acid testing, contact places and close contacts of positive people, etc.
Correlation Analysis
-
Personal self-examination and reporting information form and nucleic acid sampling and testing information form: It can analyze the relationship between symptoms reported by individuals and nucleic acid test results, as well as the impact of symptoms and test results on groups of different ages, genders, and ethnicities.
-
Place information table and place code scanning information table: It can analyze the code scanning situation in different places, and understand which places are easier for people to scan codes; it can also analyze the situation of people with abnormal body temperature in places, and understand which places have loopholes in the epidemic prevention work.
-
Personal self-examination report information form and site code scanning information form: According to the symptoms reported by individual self-examination, analyze the occurrence of symptoms in different places, and understand which places need to further strengthen the epidemic prevention measures.
-
Nucleic acid sampling and testing information form, personal self-examination and reporting information form, and site code scanning information form: it can analyze the travel situation of positive people, track close contacts, and take timely isolation measures.
-
Task1
Based on the nucleic acid test records of a positive person, Baseline can find out the places he has been to within 14 days before and after the test, and then find out the people who have been to these places, and then identify possible close contacts. The specific implementation steps are as follows:
-
First, through the incoming positive person ID, the test record of the positive person is screened out in the nucleic acid test records, and the sampling and testing time of the positive person are obtained.
-
Next, according to the place ID of the positive person at the time of sampling, the list of places where the first positive person is located is determined.
-
Then, splicing the positive person’s ID and the location code scanning information table to obtain the places where the positive person went for 14 days before and after (the list of places where the second positive person is located).
-
Merge the two place lists and deduplicate them.
-
Finally, merge all User_ids in the location code scanning information table with the location information table, and filter through the location list and time to track the ID of the close contact
Based on the nucleic acid test records, Baseline can find out the places that positive people have visited within 14 days before and after the test, and find out possible close contacts through these places.
# 获取阳性者信息
positive_user_id = df_nucleic_acid[df_nucleic_acid['jg'] =='阳性']['user_id'].values.tolist()
def Potential_contacts(df_people,df_place,df_self_check,df_scan,df_nucleic_acid,positive_user_id):
# 筛选出阳性者的核酸检测记录
df_positive_test = df_nucleic_acid[df_nucleic_acid['user_id'] == positive_user_id]
# 获取阳性者的检测时间
positive_test_time = pd.to_datetime(df_positive_test['cysj'].iloc[0])
df_self_check['dump_time'] = pd.to_datetime(df_self_check['dump_time'])
df_scan['create_time'] = pd.to_datetime(df_scan['create_time'])
# 获得阳性人员核酸检测的场所
positive_users_place1 = pd.merge(df_positive_test, df_place, on='grid_point_id')['name'].tolist()
# 获得阳性人员在测验时间前后14天去的场所
positive_users_place2 = pd.merge(df_positive_test, df_scan, on='user_id')[['user_id','create_time','cysj','grid_point_id_y']]
# 计算前14天和后14天
delta = pd.Timedelta(days=14)
# 计算最小时间和最大时间
min_date = positive_users_place2['cysj'] - pd.Timedelta(days=14)
max_date = positive_users_place2['cysj'] + pd.Timedelta(days=14)
# 筛选出符合要求的数据
mask = (positive_users_place2['create_time'] >= min_date) & (positive_users_place2['create_time'] <= max_date)
positive_users_place2 = positive_users_place2.loc[mask, ['user_id', 'grid_point_id_y']]
positive_users_place2 = positive_users_place2.rename(columns={'grid_point_id_y': 'grid_point_id'})
positive_users_place2 = pd.merge(positive_users_place2, df_place, on='grid_point_id')['name'].tolist()
# 将两个列表合并去重
positive_place = list(set(positive_users_place1+positive_users_place2))
# 获取去过上述场所的人员
# 按照密接时间筛选
df_potential_contacts = df_scan[(df_scan['create_time'] >= positive_test_time - pd.Timedelta('14D')) & (df_scan['create_time'] <= positive_test_time + pd.Timedelta('14D'))]
# 按照场所筛选
df_potential_contacts = df_potential_contacts[df_potential_contacts['grid_point_id'].isin(df_place[df_place['name'].isin(positive_place)]['grid_point_id'])]
# 整合信息并按照要求输出
result = pd.DataFrame({
'序号': range(1, len(df_potential_contacts)+1),
'密接者ID': df_potential_contacts['user_id'].values,
'密接日期': df_potential_contacts['create_time'].dt.date.astype(str),
'密接场所ID': df_potential_contacts['grid_point_id'].values,
'阳性人员ID': [positive_user_id] * len(df_potential_contacts)
})
return result
For this question, a function named Potential_contacts is encapsulated. The purpose of this function is to find all the information of people who may have contact with the positive person.
The specific logic of the function is as follows:
- Get the nucleic acid test record and test time of the positive person corresponding to positive_user_id from df_nucleic_acid.
- Convert time columns in df_self_check and df_scan data frames to datetime type.
- Get the positive_users_place1 list of places that positive_user_id has visited at the nucleic acid detection time point from df_place.
- Get the positive_users_place2 list of places that positive_user_id visited in the 14 days before and after the nucleic acid detection time point from df_scan.
- Merge positive_users_place1 and positive_users_place2 to get positive_place, that is, all the places positive_user_id has been to.
- From df_scan, df_potential_contacts is screened out from df_potential_contacts who have scan code records 14 days before and after positive_test_time (that is, potential close contacts).
- Filter out the places in positive_place from df_place, and match the grid_point_id of these places with the grid_point_id in df_potential_contacts to get the location information of all potential close contacts.
整合潜在密接者的信息和阳性者的信息,并返回一个数据框,其中包含序号、密接者 ID、密接日期、密接场所 ID 和阳性人员 ID 等信息。
Task2
def get_sub_contacts(df_potential_contacts, df_scan):
# 修改列名,方便拼接
df_potential_contacts = df_potential_contacts.rename(columns = {'密接场所ID':'grid_point_id'})
# 筛选出所有在密接者场所出入过的UserID
contacts = pd.merge(df_potential_contacts,df_scan,on='grid_point_id')
# 去除密接者ID
contacts = contacts.drop(contacts[contacts['密接者ID'] == contacts['user_id']].index)
# 计算前后半个小时
delta = pd.Timedelta(minutes=30)
# 筛选出次密接者
mask = (contacts['create_time'] >= contacts['密接日期']-delta) & (contacts['create_time'] <= contacts['密接日期']+delta)
contacts = contacts[mask]
# 整合信息并按照要求输出
result = pd.DataFrame({
'序号': range(1, len(contacts)+1),
'次密接者ID': contacts['user_id'].values,
'次密接日期': contacts['create_time'].values,
'次密接场所ID': contacts['grid_point_id'].values,
'阳性人员ID': contacts['密接者ID'].values
})
return result
该函数的具体逻辑如下:
- 将df_potential_contacts中的 "密接场所ID "列重命名为 “grid_point_id”。
- 合并df_potential_contacts和df_scan中的grid_point_id列,以找到所有曾与密接者去过同一地点的用户。
- 删除任何用户ID与密接者ID相匹配的行,因为我们不想包括自我接触。
- 在密接者日期周围设置一个30分钟的时间窗口,筛选出在这时间区间内与密接者接触的用户。
为了找到次密接者,我们需要了解密接者密接期间所在的地点和与之接触的人员。
- 这段代码的逻辑是基于一个假设:
- 如果两个人曾经在同一个时间段内出现在同一地点,那么他们可能会接触到彼此,从而增加了被感染的风险。
-
因此,该函数首先将两个表格 (df_potential_contacts 和 df_scan)合并,找到所有在与密接者相同的场所出现过的用户。
-
接下来,该函数将筛选出密接者密接时间的前后半小时内有过接触的用户。
具体地,该函数使用 Pandas 库中的 Timedelta 函数设置一个时间窗口,
然后将 create_time 列中的日期和时间与 密接日期 进行比较,筛选出在这个时间窗口内的接触记录。
-
最后,根据result格式输出答案
Task3
病毒传播指数可以根据现有的数据表格中的核酸采样检测信息表和场所码扫码信息表来计算。一种常用的方法是使用传染病流行病学中的基本再生数R0,它代表一个感染者平均会传染多少其他人。
首先,我们可以根据场所码扫码信息表中的数据计算每个场所的平均体温,并根据该平均体温和感染者的体温来确定感染概率。最后,我们可以使用基本再生数公式(R0 = 感染概率 × 平均接触人数)来计算病毒传播指数。
具体步骤如下:
-
根据场所码扫码信息表中的数据,确定每个场所的温度分布的平均值和标准偏差。
-
根据场所码扫码信息表中的数据,确定感染者的体温。
-
根据感染者的体温和场所的平均体温,计算感染概率,例如P = exp(-(38-37)2/2σ2),其中σ是体温分布的标准差。
-
根据密接者表中的数据,确定平均接触人数。
-
计算基本再生数R0 = 感染概率 × 平均接触人数。
将计算出的病毒传播指数与接种疫苗信息表中的数据进行比较,分析接种疫苗对病毒传播指数的影响。
- 第一步:确定每个场所的温度分布的平均值和标准偏差
df_scan['temperature_mean'] = df_scan.groupby('grid_point_id')['temperature'].transform('mean')
df_scan['temperature_std'] = df_scan.groupby('grid_point_id')['temperature'].transform('std')
- 第二步:根据场所码扫码信息表和核酸采样信息表,确定感染者的平均体温
df_positive = pd.merge(df_scan, df_nucleic_acid[df_nucleic_acid['jg'] == '阳性'][['user_id']], on='user_id', how='inner')
df_positive['temperature_mean_positive'] = df_positive.groupby('grid_point_id')['temperature'].transform('mean')
- 第三步:计算感染概率
df_positive['infection_prob'] = np.exp(-((df_positive['temperature_mean_positive'] - df_positive['temperature_mean']) ** 2) / (2 * df_positive['temperature_std'] ** 2))
- 第四步:根据密接者表中的数据,确定平均接触人数
# 根据阳性人员ID和密接场所ID进行分组,并统计每个组内密接者数量
grouped = result1.groupby(['阳性人员ID', '密接场所ID'])['密接者ID'].count().reset_index()
# 将统计结果返回到原数据集中
result1 = pd.merge(result1, grouped, on=['阳性人员ID', '密接场所ID'], how='left')
result1_count = result1.rename(columns={'密接者ID_y': '密接者数量'})
result1_count['平均接触人数'] = result1_count.groupby(['阳性人员ID', '密接场所ID'])['密接者数量'].transform('mean')
df_positive = pd.merge(result1_count, df_positive, left_on='阳性人员ID', right_on='user_id')
- 第五步:根据感染概率和每个感染者在每个场所的平均接触次数计算病毒传播指数。
df_positive['label'] = df_positive['infection_prob'] * df_positive['平均接触人数']
- 第六步:与疫苗接种信息表合并
# 疫苗接种信息表
df_vaccine_info = pd.read_csv('../datasets/附件7.csv',encoding = detect_encoding('../datasets/附件7.csv'))
df = pd.merge(df_vaccine_info, df_positive, on='user_id')
# 去除没有label的数据
df = df.dropna()
- 第七步:拟合数据,分析特征重要性
col = ['age', 'gender','inject_times', 'vaccine_type','label']
df = df[col]
# 对类别列进行数值编码(你也可以用其它编码进行特征工程)
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestRegressor
# 创建 LabelEncoder 对象
le = LabelEncoder()
# 对 nject_times 和 vaccine_type 进行数值编码
df['nject_times'] = le.fit_transform(df['nject_times'])
df['vaccine_type'] = le.fit_transform(df['vaccine_type'])
# 创建随机森林回归模型
rf = RandomForestRegressor(n_estimators=100, random_state=2023)
# 拟合数据
X= df.drop('label',axis=1)
y = df['label']
rf.fit(X, y)
# 得到特征重要性
importances = rf.feature_importances_
# 将特征重要性排序
indices = np.argsort(importances)[::-1]
# 将特征名称按照重要性排序
names = [f'Feature {i}' for i in range(X.shape[1])]
sorted_names = [names[i] for i in indices]
# 绘制特征重要性柱状图
plt.figure()
plt.title("Feature Importance")
plt.bar(range(X.shape[1]), importances[indices])
plt.xticks(range(X.shape[1]), sorted_names, rotation=90)
plt.show()
The scheme of Task3 belongs to throwing bricks to attract jade, just refer to the ideas
-
In this scheme, many factors are not taken into account, only age, gender, and vaccination category are considered in the modeling
-
In this scheme, there are many decisions that can be optimized, such as the temperature distribution of each site
Tips: If you want to use the temperature distribution of each place defined by this code, you need to make assumptions. Because the temperature distribution changes with time. So when you do it, you can take time into account, and calculate the temperature distribution at each moment according to the time.
-
Another is the definition of the virus transmission index. In this scheme, we think that the basic reproduction number is our virus transmission index. The definition of label is different, which is likely to affect the solution of the whole question.
-
In short, it is relatively one-sided, and the consideration is not very comprehensive. If there is anything you don’t understand, just leave a message below. It is only for learning and communication (not necessarily correct)
Task4
Just wait for the update
Category of website: technical article > Blog
Author:kkkkkkkkkkdsdsd
link:http://www.pythonblackhole.com/blog/article/25275/9c146d33d5d9fa06b8b3/
source:python black hole net
Please indicate the source for any form of reprinting. If any infringement is discovered, it will be held legally responsible.
name:
Comment content: (supports up to 255 characters)
no articles